{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
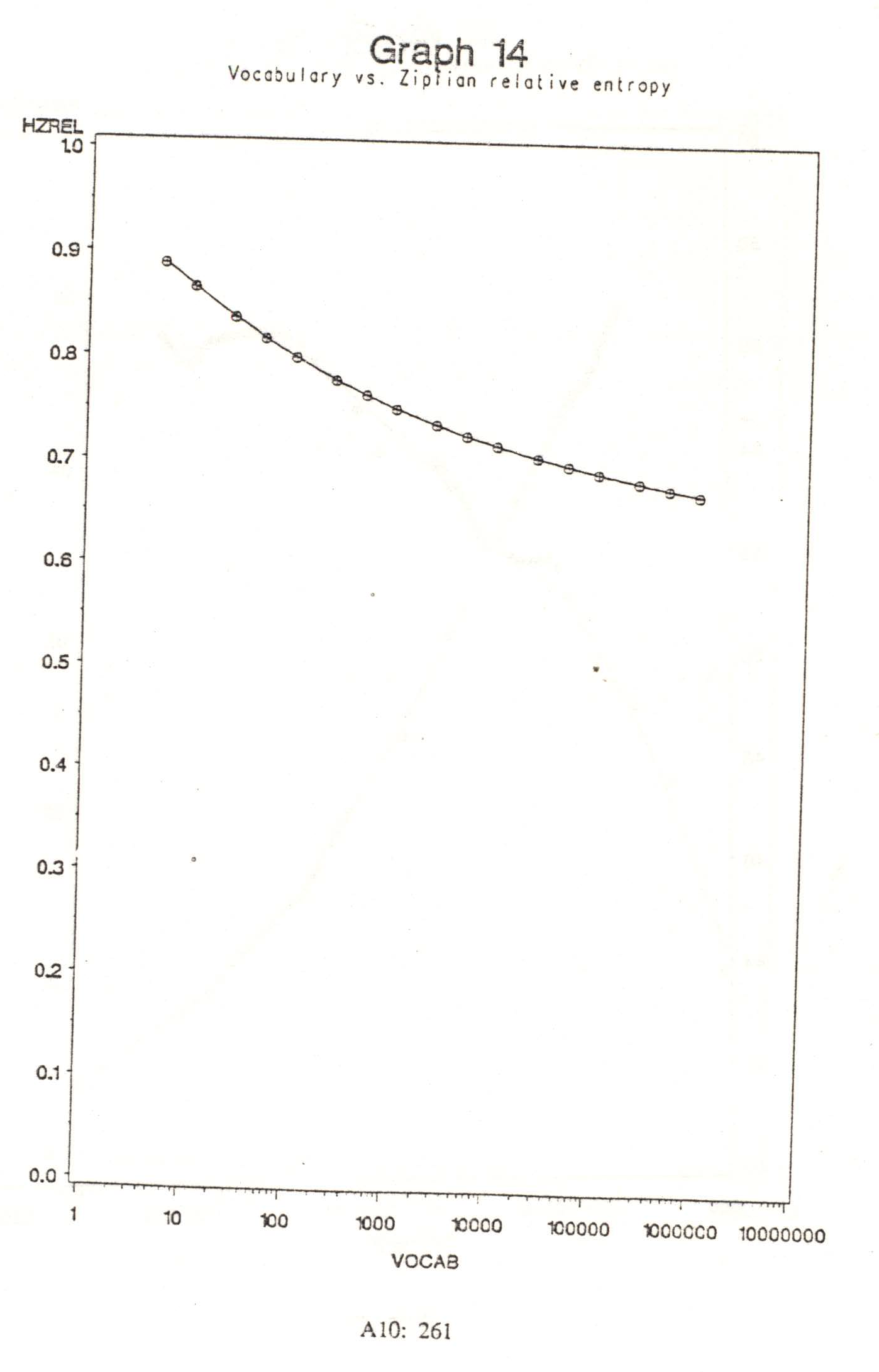{kind=link}
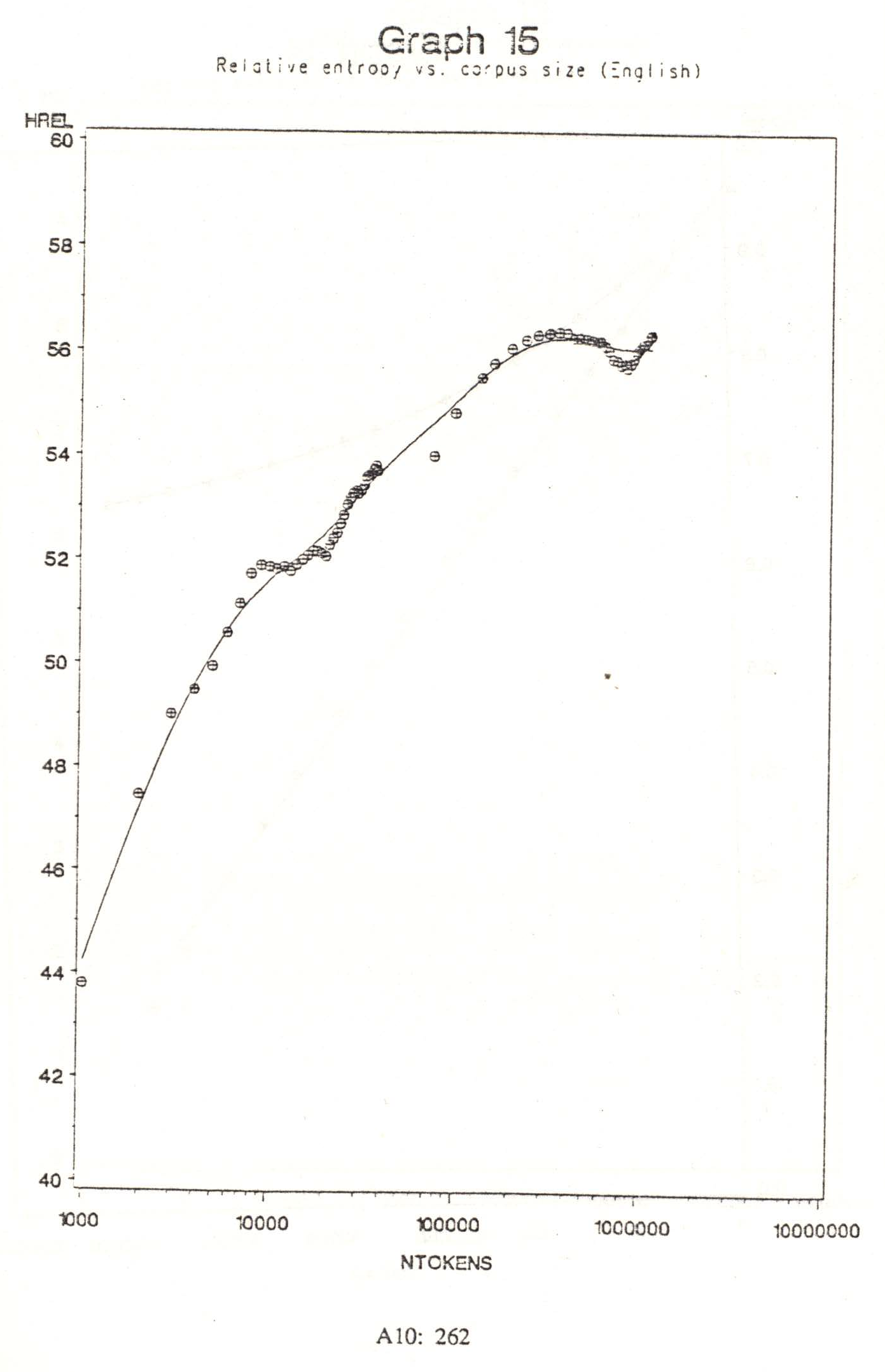{kind=link}
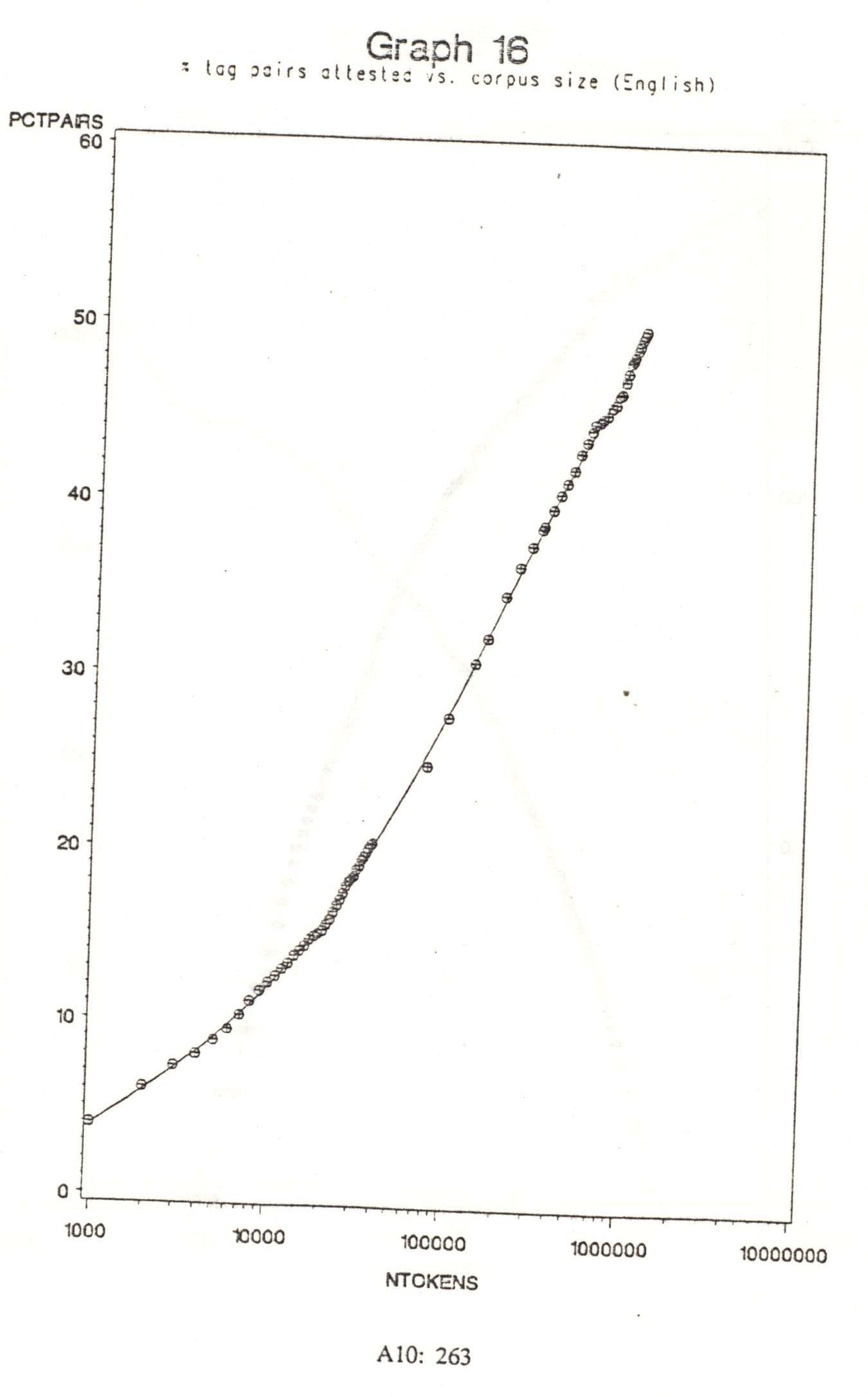{kind=link}
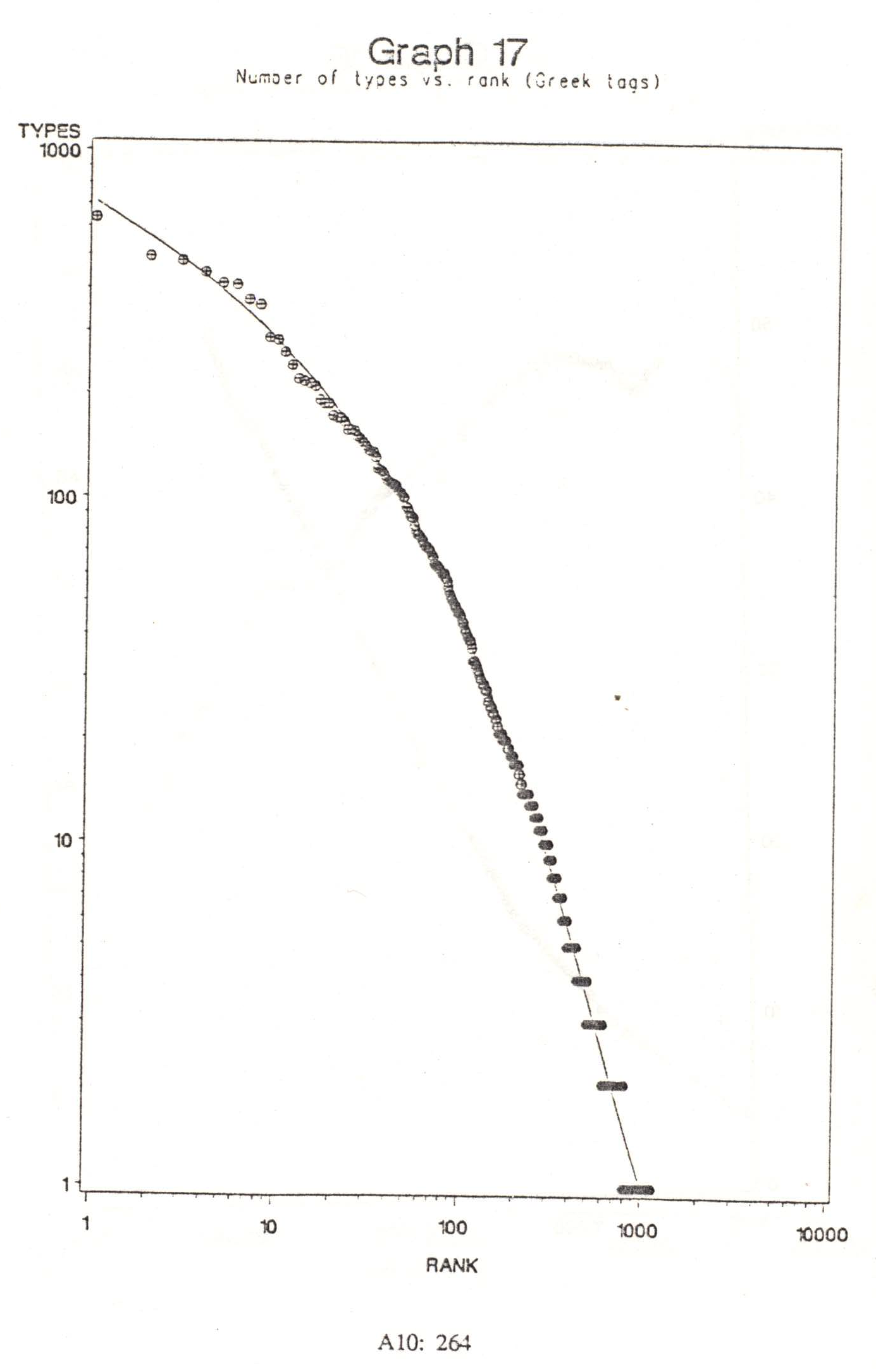{kind=link}
{kind=link}
{kind=link}
Edition information
The original published form of the dissertation is available from University Microfilms, order number 9002217.
This electronic edition was converted from the original word-processor files to XHTML by the author. BBEdit did most of the table conversions automatically. I did the rest via an awful lot of regex changes and hand-editing.
This is how a recently-added note looks.
Differences of which the author is aware:
- I have omitted most of the front matter (Preface, CV, Table of Contents).
- The text has been made into one HTML file for each chapter and appendix (plus a CSS file to control layout.
- I have added the original page numbers at the end of the titles of larger sections, in the same color as notes and corrections, like0; and added hierarchical section-numbers at the start of all headings. These should correspond exactly to the sequence and levels evident in the original Table of Contents (although no explicit section-numbering appeared there).
- I have added many links. This starting file has the Abstract and links to all the other files, graphs, and tables. Chapters have a "next" link at the end, to the next file. The Bibliography has section dividers and links at the top to get the the start of each letter in the alphabetical list (by first author).
- Citations have been linked to the corresponding Bibliography entries. During this process I discovered a few omissions and typos in the Bibliography, whose correction is indicated using the convention described above.
- I have gathered the footnotes here, and they are linked from their original attachment points in the text. I have renumbered them using their original page, plus a dot, plus their original superscript symbol.
- Equations have been manually converted to MathML; a few are incomplete.
- Italics were lost. I've re-tagged some, but probably not all.
Copyright 1989, 2013, Steven J. DeRose.
This work by Steven J. DeRose is licensed under a Creative Commons Attribution - No Derivatives license. This means you are free to reproduce or distribute it, but must cite the source, and cannot make changes. For further information on this license, see http://creativecommons.org/licenses/by-sa/3.0/.
For the most recent version, see http://www.derose.net.

This work is licensed under a Creative Commons Attribution-NoDerivs 3.0 Unported License.