Chapter 2: Theoretical Foundations
Linguistic foundations5
Words
The term word,
while superficially intuitive, conceals some complexity. It is a term which is usually taken for granted, and never offers any difficulty until we try to state precisely what we mean by it
(Adams 1973, p. 7). Indeed, it may mean at least the following things:
A word instance is the least abstract meaning I will consider. It refers to a single occurrence in a text, and is synonymous with word token. In speech, word tokens can be difficult to separate by algorithm, but in modern written language they are generally explicitly marked, being separated from preceding and following elements by spaces or punctuation marks.
The term word form is a bit more abstract: it refers to the collection of all word instances which share spelling or pronunciation. In general, all instances of a particular form share not only their spelling or pronunciation, but also certain aspects of meaning. However, this need not be true. For example, swallow
can refer either to a gustatory act (either as noun or verb) or to a bird (as noun); these two general meanings are quite distinct, nevertheless swallow
constitutes one word form. Since I am working with written language, record
also constitutes one word form, even though it has two senses which are consistently distinguished by pronunciation. Word type
is essentially synonymous with word form for my purposes, though the former term has also been used to refer to the following concept, word form-set.
I will use the term word form-set to refer to a commonplace linguistic abstraction, a set of words forms which in general have similarity of form and meaning. For example, the word forms go,
goes,
gone,
and went
constitute one word form-set, or, as we commonly say, one word.
Finally, I use the term lemma to refer to a privileged member of a form-set, which is the conventional means of referring to the set as a whole. In English, we commonly use the singular of nouns, and the present non-third-person-singular of verbs, to represent a word form-set for convenient reference: the word ‘go’.
In Greek, the first person singular present active indicative form of verbs serves a similar function.
The relation between word forms and lemmas is not always simple. Not only may one lemma label a form-set with many forms; there are also forms which are members of more than one lemma’s form-set. These forms are commonly called homographs or homophones; they will not be of significant concern in this thesis, except for those cases where a homograph’s different senses or lemma memberships are also of different grammatical categories.
For brevity, I will frequently use word
to mean word form
, and lemma
loosely to refer to the form-set labelled by a lemma.
Grammatical categories
A grammatical category is a label for a class of word instances, the members of which share characteristics such as distribution or context. The instances of a single word form will generally represent only a small number of possible grammatical categories, and of those categories, the instances are likely to represent some much more frequently than others. Ideally words assigned to the same equivalence class would be interchangeable in all syntactic contexts, but of course semantic and other factors preclude this in reality. Therefore the choice of grammatical categories is somewhat subjective, and inevitably ignores certain distinctions deemed irrelevant for a given purpose. For example, mass and count nouns in English can for many purposes simply be considered nouns, ignoring certain systematic differences in their distributional patterns. I will call the names of grammatical categories tags.
Grammatical categories are themselves categorized; one important distinction among them is that of open vs. closed classes. The open classes (mainly noun, adjective, verb, and their sub-categories) tend to carry a greater load of referential information. New members may be coined easily. The closed classes (various types of function
words) carry a greater load of structural information, and cannot so easily be coined. Bradley (1983, pp. 1-9) discusses evidence for a fundamental division of the lexicon on this basis. She cites the following major differences:
- Number of types — the open classes have many members; the closed classes have few.
- Word length — closed class items tend to be short; open class items vary more. Miller, Newman, and Friedman (1958, p. 382) report average lengths of 3.13 and 6.47 letters, respectively.
- Average word frequency — closed class items tend to be of high frequency.
- Ambiguity — open class items are more (categorially) ambiguous.
She cites evidence from speech errors, language acquisition, aphasia, response-time experiments, and other sources, to support the claim that separate processing mechanisms handle the two classes. However, I am not convinced that the claim that open class items are more ambiguous is correct; it may be an artifact of traditional systems for parts of speech, which made few of the desirable distinctions among closed class items.
Data from the Brown Corpus show that a significant number of closed-class words are ambiguous (see Appendix 4); these words are also quite frequent. The closed classes are many, but they have a fixed number of members. Thus, these words pose constrained but frequent problems in tagging and disambiguation. One may (fortunately) expect even a moderate-sized dictionary to contain all words which are members of closed classes; this eases the task of disambiguation for these words.
The open classes have unbounded membership. Therefore, one cannot achieve a complete dictionary of open class words. Fortunately, the number of closed classes is relatively small, a fact which will play a role in the disambiguator’s ability to deal with neologisms. 8.1 Since even a small dictionary will contain virtually all function words, words not known will almost certainly be members of open classes.
Traditional grammarians defined 8 major categories for English: noun, verb, adjective, adverb, pronoun, conjunction, interjection and preposition
(Sinclair 1987a).8.2 But there are many words which do not quite fit; in particular, there are various closed classes whose descriptions are not adequately described within this eight-class framework. Winograd, for example, distinguishes 10 categories to account for the subcomponents of English noun phrases (Winograd 1983, p. 513):
| Pre-determiner | half, both, all |
| Determiner | the, a, this, every |
| Ordinal | first, second, last |
| Cardinal | one, two, three |
| Describers | big, purple, enchanted |
| Classifiers | stone, retaining |
| Head | walls, person, ones |
| Restrictive qualifiers | in town, that flies |
| Nonrestrictive qualifiers | John, whom you already know |
| Possessive marker | -’s |
From this list one can easily construct plausible NPs, e.g.: both the last two big, purple, enchanted stone retaining walls in town, which you have already seen.
The word order is largely inflexible, indicating that these words are not members of a single class, or even of a few classes. Indeed, Winograd points out that even these classes are not enough: The exact rules for selecting and ordering these elements are very subtle; they have to do with a kind of scale of ‘inherentness’ on a semantic level, and nobody has really worked out a good formalism for them
(Winograd 1983, p. 515).
Miller and Chomsky (1963) describe a method for inducing a set of grammatical categories for a language, which is in a particular statistical sense optimal.
Jelinek (1985) also discusses methods for category induction. Such methods work by comparing the environments in which word forms are inter-substitutable, and grouping words with the same or similar distributional patterns into classes. In this thesis, however, I will work with already established sets of categories. Kučera (1981) considers the related problem of inducing not only categories, but an entire finite-state grammar given a limited sample of the language which the grammar generates.
Word forms in many languages reflect an even more finely specified set of categories. In addition to major category, a word form may be marked for minor or inflectional categories which determine classes such as plural
or third person singular aorist passive indicative.
The fineness of categorial distinction used affects not only the degree of categorial ambiguity, but the degree of other sorts of ambiguities, such as structural. For example, he decided on the boat
is structurally ambiguous only if the categorial system used fails to distinguish two particular uses for on
: namely as a locative preposition, or as part of a two-part verb (what the Brown Corpus labels an adverb/particle
).
English tag-set
For English I will use the set of categories devised for the Brown Corpus. It has been widely used in subsequent computational analysis (sometimes with modifications), and I will continue to use it. Greene and Rubin (1971, pp. 3-21) discuss the derivation of this tag-set. Kučera (1982, p. 169) characterizes it as a taxonomy of 87 grammatical classes . . . (including six syntactically useful punctuation tags), representing an expanded and refined system of word-classes, supplemented by major morphological information and some syntactic information.
The Brown Corpus tag set distinguishes the usual major categories adjective, noun, adverb, and verb, each with several subdivisions reflecting English inflectional morphology (e.g., plurals, possessives, past participles, etc.). Pronouns and proper nouns are distinguished, with the former marked for case. Quite a few other categories are provided, including special tags for function words. The unusually important word forms related to be, do, and have, and the various wh- words, also have special tags.
Additional markers indicate words in headlines and titles, foreign words, and metalinguistic uses, i.e., words which are mentioned rather than used (as in the word if has two letters
). Punctuation marks are treated as separate tokens on par with words, and receive their own tags (Francis and Kučera 1979, pp. 15-25). The full table of tags appears in Appendix 2, which is based on Francis and Kučera (1979, pp. 23-25; 1982, pp. 6-8).
Some later tag sets split contractions, and/or the 's
of possessive, into separate tokens, thus often but not always avoiding the need to attach two tags to one token (consider "cannot", "gonna", the 3rd-millenium shorthand "ima", and so on).
Greek tag-set
In inflected languages such as Greek, the extensive inflectional information within each word form results in a different and much larger set of categories. In Greek, for example, many functions which are expressed in English by word order or by separate lexical items, are instead expressed by affixes. Examples include case, tense, mood, number, and gender. The number of categories is large (nearly 1200), due to the interaction of multiple affixes. There are relatively few major-class ambiguities in Greek; inflectional morphology virtually precludes such confusions.11.1 However, within paradigms there is frequent ambiguity in which a given word form can represent more than one of the entries in a given paradigm. It is at this level that I will investigate the applicability of stochastic methods. Consider Table 2, showing the paradigm for one typical class of Greek adjective (from Smyth 1976, p. 74, transliterated; ambiguous forms appear in boldface type):11.2
| Singular: | ||||
|---|---|---|---|---|
| Case | Feminine | Masculine | Neuter | |
| Nominative | agathe: | agathos | agathon | |
| Genitive | agathe:s | agathou | agathou | |
| Dative | agathe: | agatho: | agatho: | |
| Accusative | agathe:n | agathon | agathon | |
| Vocative | agathe: | agathe | agathon | |
| Plural: | ||||
| Case | Feminine | Masculine | Neuter | |
| Nominative | agathai | agathoi | agatha | |
| Genitive | agatho:n | agatho:n | agatho:n | |
| Dative | agathais | agathois | agathois | |
| Accusative | agathas | agathous | agatha | |
The nominal paradigm is much the same; indeed, one need only prefix an article to use an adjective substantively. None of the forms in this paradigm could be mistaken for a verbal form (although o:n is a common ending on adverbs); but within the adjectival paradigm many specific ambiguities arise. For example, masculine and neuter forms are often (but not for all words, or in all forms) indistinguishable; the genitive plural is the same in all genders; and only the masculine gender distinguishes the vocative and nominative forms. In fact, two thirds of the forms in the paradigm shown are ambiguous.
Because not all lexical items exhibit the same range of ambiguities, it is sometimes true that one word in, say, a noun phrase provides sufficient information to disambiguate another word (or words). Since (even in Greek) noun phrases tend to be contiguous, collocational methods can help to resolve this class of categorial ambiguity.
The Greek tag set I use is that of the Analytical Greek New Testament (Friberg and Friberg 1981a, 1981b). It is described more fully in Appendix 7. It assigns all words to one of the major categories noun, verb, adjective, determiner, preposition, conjunction, or particle. Beyond that, case, number, gender, person, mood, tense, and voice are marked in much the traditional ways.
Prepositions are marked for the case they govern (this cannot be determined from the word form); conjunctions are marked for sub-, co- or super-ordination; and particles are marked as sentential, interrogative, or verbal. The category adjective is subdivided, and includes adverbs, numbers, demonstratives, and so on. Participles are indicated as such, and are marked for case, number and gender in the same fashion as are nouns.
The 1155 fully expanded tags which occur in the Greek New Testament are listed, with frequencies, in Appendix 8. Though large, this set of tags is a simplification of the original. The Friberg and Friberg tags mark not only major category and inflectional information, but also some high-level syntactic and even semantic interpretations.
For example, a used-as marker may conjoin tags under a single word, and the following tag(s) may bear any of several relations to the preceding. Semantically vocative nouns may be marked as nominative used-as vocative; but Matthew 1:20 reveals a quite different function for the used-as marker. There a determiner (appropriately subcategorized) is said to be used-as the crasis (i.e., contraction) of a pronoun and a pronominal adjective. Further, some words have multiple tags conjoined by and
and two different or
s.
All such compound tags have been simplified in my research. On the other hand, punctuation marks are not tagged in this Greek New Testament corpus; I therefore added a tag to denote sentence end. This tag was assigned whenever a word was found to end in a period, a safer practice in Greek that it would be in English, since abbreviations are not marked by periods.
Words and categories
One can imagine a system in which every word form had exactly one possible grammatical category, and indeed some word forms both in English and in Greek may have this property. However, this is not always (or perhaps even usually) the case. When it is, the word form is said to be unambiguous.
When one word form has several alternative categories, it is said to be ambiguous. Such word forms are the focus of my attention in this thesis.
One cannot prove a word form to be unambiguous by any amount of corpus research, for it is always possible that the next instance of the word form will demonstrate that it can be used in another category. But even considering only those words attested as ambiguous within the corpora I examine, the degree of ambiguity is quite high in both English and Greek. As noted earlier, in the Brown Corpus about 11% of all types (20% if hapax legomena are excluded), which represent 48% of all tokens, are found to be categorially ambiguous; in the Greek New Testament, about 9% of types, and 47% of tokens, are categorially ambiguous.
When one word form has a sequence of categories all of which apply to a single instance of the form, the form is said to be a contraction. In reference to Greek, the term crasis is more commonly used. There are not many contractions in either English or Greek; a table for English is available in DeRose (1985, p. 51); a table for Greek is in Appendix 9.
When a sequence of word forms is assigned but one category, the sequence is said to be an idiom. This definition is different from perhaps more common definitions in terms of semantic opacity or Arbitrariness and Non-Analysability
(Nagy 1978, p. 289).
Fraser defines idiom
to mean a constituent or series of constituents for which the semantic interpretation is not a compositional function of the formatives of which it is composed
(Fraser 1970, p. 22). But since I am here concerned with categorial rather than semantic ambiguity, I will use the term to refer to phrasal elements whose categorial content is not predictable in the usual manner. Blackwell (1987, pp. 111-112) characterizes such idioms as certain combinations of words [which] assume a ‘gestalt’ identity: their grammatical function differs from the syntactic sum of their parts,
and gives to and fro
as an example. In this idiom to
functions as an adverb, which it does not function as elsewhere. There is also a class of idioms, whose members function as if they were each a single lexical item. One example is so as to,
which functions as if it were an infinitive marker (Blackwell 1985, p. 7); two similar cases which are tagged as single prepositions in the LOB corpus are because of
and such as
(Garside 1987, p. 31).
English includes a number of two-part verbs, which may be viewed as a special case of categorial idioms. Perhaps the best known example is look up.
One can look up a hill
or look up a word
; but one cannot look a hill up
in the former sense, despite the acceptability of look a word up.
The Longman Dictionary of Phrasal Verbs (Courtney 1983) provides a wealth of information about such verbs in English.
In the Brown Corpus discontiguous verb fragments are tagged RP (adverb/particle) rather than IN (preposition) (Francis and Kučera [actually Kučera and Francis] 1967, p. 25). The problems which these particles raise are subtle, and deserve fuller treatment than can be given them within the scope of this thesis. I will not consider them further; rather, use of the RP tag will be retained.
The categorization system used for the Brown Corpus does not provide idiom tags other than RP. The Lancaster - Oslo/Bergen Corpus of British English (see Beale 1985, Blackwell 1985) uses ditto tags,
in which the first word of an idiom is given the tag appropriate to the idiom as a whole, and the remaining words are given that tag with a special suffix indicating continuation. Blackwell does not discuss whether discontiguous idioms are tagged in the same manner. I follow the practice of the Brown Corpus in this thesis.
Compound words are unproblematic, because they function as instances of a single lexical category. In English, many apparent compounds such as blueberry
or arc-pair
can be assigned a single category from among those otherwise motivated for non-compounds. In Greek, similarly, there is a large class of lexicalized preposition + verb combinations which function just like other verbs. It is often true that the word class of the compound is that of its last element
(Winograd 1983, p. 545). But the rules governing compound words are very complex; a thorough discussion of English compounds is provided by Adams (1973).
Punctuation
Punctuation elements are important cues to adjacent categorial structures. For example, an article in English is far more likely to appear immediately after a period than immediately before. Even some semantic or structural ambiguities may be resolved by reference to punctuation (see Hirst 1983, p.146). Thus, it is preferable to treat punctuation items as tagged elements similar to words, and to use them in all collocational analyses.
Kučera and Francis (1967, pp. xx-xxi) describe several kinds of unusual tokens which are encountered in written texts, such as numbers, formulae, and so on. Many of these can be assigned acceptable categories solely on the basis of their form. When possible these should be handled algorithmically, for one could not build a lexicon large enough to contain, say, all possible dollar amounts, ordinal or cardinal numbers, or formulae. I have excluded forms containing only digits and punctuation marks from the dictionary I use, but other atypical word
forms have been included. The excluded forms are handled by simple examinations of what characters they contain.
Corpus linguistics and language corpora
Corpus linguistics is that branch of linguistics in which large collections of natural language data are the objects of analysis. This stands in contrast to approaches based solely on native speaker intuitions, and so Aarts and van den Heuvel note that corpus linguistics has been characterized as a controversial and, to some, disreputable activity.... although a gradual change seems to be taking place. . .
(1985, p. 303).
Although it is not my purpose in this thesis to discuss the role of corpus linguistics or its relation to other methods of analysis, I will briefly present a few of its advantages and limitations, and refer the reader to several more detailed discussions.
Corpus linguistics has several advantages over intuitive methods. First, it enforces a certain accountability on the analyst; it is not possible to choose exactly the data for which one’s theory must account (cf Johansson 1985, p. 208, Leech 1987, p. 3). Second, a good corpus very frequently reveals to the analyst linguistic structures which might never have been found by intuition, however effective intuition may be for judging them once they have been found (cf Aarts and van den Heuvel 1985, pp. 304f, 309ff). Third, a corpus provides a quantitative and repeatable measure of a theory’s ability to account for language behavior, preventing the case where rules designed for a set of subtle constructions fail on a far more prevalent construction which was not under consideration (ibid). And fourth, it reveals the limitations of grammars which cover only a carefully chosen subset of a language (cf Sampson 1987a, pp. 16-20).
Aarts and van den Heuvel mention three criticisms which have been made of corpus linguistics: first, that conclusions based on corpus linguistics lack general significance; second, that intuitions are excluded; and third, that corpus data are degenerate
(Aarts and van den Heuvel 1985, p. 304).
The first criticism is strictly a matter of how well the corpus used reflects the language as a whole. This is a function of corpus size and content, but most importantly, it may be measured. For example, multiple corpora may be obtained and compared, and various statistical measures may be applied to estimate how well they represent the language as a whole. In the same way, as a corpus is being collected successively larger subsets can be compared to see if particular phenomena have become stable, or can be expected to become stable above a certain corpus size. For example, if one is interested in the average length of English words, a very accurate estimate with high statistical significance can be reached even using a very small corpus. A much larger corpus is needed for grammatical generalizations, and an extremely large corpus would be needed for large-scale phenomena such as long-distance agreement or movement.
The second criticism, that intuitions are excluded, is not inherent to corpus linguistics, and is not generally true. Rather, the corpus linguist uses corpora as discovery tools, which reveal linguistic structures then subjected to analysis by other means including intuition. For example, the fact that the first sentence in a sample of newspaper text I examined listed two political candidates as having placed sixth and seven [sic]
would not cause me to discard the (intuitive and independently supported) distinction between cardinal and ordinal numbers, or to loosen the syntactic constraints on conjunct structures. However, its understandability may reveal something about the similarity of the categories involved, and about the human language processing mechanism. This would be particularly true if this class of substitution is frequent, or possibly even regular in some dialect. These are questions about which a single linguist would be unlikely to have reliable intuitions. It is an important virtue of corpus-based methods that in such cases rather than depend on a sampling procedure limited by the attention and interest of the grammarian, it will be possible, for example, to extract all instances. . .
(Francis 1964, p. v), and to examine them for regularities or as evidence of other phenomena to be accounted for.
The third criticism, that corpus data are degenerate,
brings us to the central issue of competence versus performance. Probably most speakers would agree that the sixth and seven
example is merely a performance error which was recorded in the newspaper. Moreover, the error might not even be due to the original utterer, but to a typist. Native speaker intuitions, it is said, allow the linguist to abstract beyond such noise and errors of performance, to the ideal language competence beyond; but the presence of speech or writing errors in the corpus is not a problem for corpus linguistics unless a corpus is construed as definitive, a mistake seldom made. Certainly no one would wish to claim that aphasic speech reveals nothing about the structure of language, even though it may contain many errors.
Many corpora exclude strongly degenerate data, thus approximating competence more closely than might be expected. Those corpora closest to reflecting pure performance, and hence most suited for the purpose of describing pure performance, are strict transcriptions of spoken language. Corpora of written language contain far fewer paralinguistic elements, slips, and other data which might be considered irrelevant to analysis. Corpora of published language, such as the Brown and the Lancaster - Oslo/Bergen (or LOB) corpora, contain even fewer spurious structures. However, corpora generally do not exclude unusual syntactic structures, neologisms, etc.; the exclusion of unintuitive data is a characteristic of the competence-based approach.
A fourth criticism might be that corpus data, being records of performance, are not the concern of linguistics. Hockett (1968, p. 39), recounting Chomsky’s orientation, notes the fundamental claim that the central concern
of linguistics is competence, and that probabilistic considerations pertain to performance, not to competence.
This of course can be true only given a certain definition of linguistics,
one which many linguists do not share. Mandelbrot (1961, pp. 211-214) discusses this in further detail, and Damerau (1971) asserts that dismissing performance phenomena is purely arbitrary.
Even Jakobson (1961b, p. 246) observes that information theoretic concerns have reentered. . . linguistics as one of its crucial topics.
The intuitive viewpoint has many merits, which have been discussed so often that there is little point in recapitulating them here. However, it too has limitations. Perhaps the most relevant one for the current purpose is that language, as it exists in the world and must be processed (whether by humans or by computers), is not entirely composed of grammatical sentences. Hockett suggests that the neat, complete, ‘grammatical’ sentence is something of a rarity
(1961, p. 235). That is, linguistic competence is seldom observed, but only reported; this may overstate the case, however, there is clearly no shortage of ungrammatical sentences in unrestricted text. The human language processing mechanism has no trouble dealing with even quite severely ungrammatical sentences, while a theory which perfectly modelled competence would remain inadequate when presented with actual language performance. And a good many people, some of them linguists, are interested in performance, whether for its own sake or as a way to an understanding of competence
(Francis 1979, p. 8).
A second limitation of the intuitive approach is that it cannot contribute directly to diachronic analysis (there being no native speaker intuition available regarding past or future states of languages), whereas corpus linguistics can. This limitation, however, is not of interest in my investigations.19.1
A third limitation is that quantitative judgements cannot be made reliably on the basis of intuition. Certainly there are degrees of acceptability for sentences, but a speaker is hard pressed to say just how ungrammatical a sentence is. Frequencies of structures in a large corpus can give some measure of use, if not directly of grammaticality.
Corpora
Many standard collections of natural language text, known as corpora, have been developed, and have been used to estimate the frequency (and hence probability) of grammatical events which are of interest. Francis has pointed out that particular corpora generally have some specific purpose, though they are often put to use for other purposes than those originally intended
(1979, p. 9).
For example, the Birmingham Corpus (see Renouf 1984, Sinclair 1987) is a collection of 12 million words, much of which was used to provide word use information for development of the COBUILD dictionary. A Dictionary of American Regional English was also prepared with the aid of a large corpus (see Francis 1979, p. 9).
The American Heritage Intermediate Corpus (Carroll 1971) is a collection of 5 million words which provided word frequencies based upon sampling materials commonly read by 3rd-9th grade American students. Two of the earliest lexicostatistical corpora were 100,000 word samples whose word frequencies were reported in Ayres (1915) and Dewey (1923). A much larger investigation was summarized in the Teacher’s Word Book (Thorndike and Lorge 1944). The original counting was reported in 1921, with an update in 1931 and another in 1944, with word counts eventually based on over 12 million words of text (although high frequency words were not counted in some portions; forms of be, come, and do were not always separated; contractions were omitted; etc.).
There are also corpora of spoken English, of particular dialects and genres, and of many other languages. But because the linguistic events which I investigate are the co-occurrences of grammatical categories, and the use of word forms as representatives of various grammatical categories, the corpora of interest for my purposes are those which have been grammatically tagged.
These include the Brown Corpus, a million word sample of edited American English prose, entirely drawn from sources first published in 1961. The 500 samples constituting the Brown Corpus are proportionately distributed across 15 genres, making this a general rather than specialized corpus. For further details see Kučera and Francis (1967), Francis and Kučera (1979, 1983). I use this corpus extensively in the investigations reported in this thesis.
Another substantial tagged corpus of English has been produced through the cooperation of researchers at Lancaster, Oslo, and Bergen, and is therefore known as the LOB Corpus. It is closely parallel to the Brown Corpus, but includes British rather than American English, and uses a somewhat different set of grammatical tags. Like the Brown Corpus, it includes 1 million words of prose published in 1961, proportionately distributed across 15 genres. The particular tag set differences are described in Sampson (1987b).
For ancient Greek the potential corpus is closed (excluding occasional unearthing of new manuscripts); a virtually complete collection of machine-readable texts is the Thesaurus Linguae Graecae (see Hughes 1987), but it has not been tagged. The Greek New Testament, however, including about 140,000 words, is available in tagged form, and I use it for the investigations reported here.
Attestation in a limited corpus21
Linguistic theories are never exhaustively descriptive; even less so are the linguistic descriptions they inspire. Particularly in the field of corpus linguistics, one must remain aware of the points at which one’s sample may not adequately represent its language as a whole. It will be the case, no matter how extensive a corpus of a given language may be, that some words will not be encountered at all, and even those which are encountered may not appear in all of their possible environments.
Attestation of words
Carroll (1967, p. 412) projects a total vocabulary of 340,193 word forms for English, based on extrapolation from the Brown corpus to one of infinite size. He also notes that even a corpus of 100 million words would likely reveal only 61% of the total projected vocabulary. The Oxford English Dictionary contains 252, 259 main entries, not including perhaps 33,000 non-overlapping entries in the supplement (Raymond and Tompa 1987, p. 144; Kazman 1986, p. 4). This is generally consistent with Carroll’s estimate, because the OED includes many obsolete words, but does not separately list most inflected forms.
The Brown Corpus vocabulary, however, is on the order of 50,000 forms, or about 15% of the projected total. Zipf’s law (see below) predicts an ideal
set of frequencies (and hence probabilities) for lexical items given a particular vocabulary size. Assuming a Zipfian distribution over an English vocabulary of 340,193 word forms, Table 3 shows the percent of total tokens which would be accounted for by varying dictionary sizes, if the dictionaries in question select items in perfect order of probability. The Brown Corpus, despite covering only 15% of the expected word forms, is ideally predicted to cover about 85% of all tokens.
| Dictionary Size | % coverage |
| 1 | 7.510 |
| 2 | 11.265 |
| 5 | 17.149 |
| 10 | 21.998 |
| 20 | 27.021 |
| 50 | 33.791 |
| 100 | 38.960 |
| 200 | 44.147 |
| 500 | 51.018 |
| 1000 | 56.220 |
| 2000 | 61.424 |
| 5000 | 68.305 |
| 10000 | 73.510 |
| 20000 | 78.716 |
| 50000 | 85.598 |
| 100000 | 90.804 |
| 200000 | 96.010 |
| 250000 | 97.686 |
| 300000 | 99.055 |
Attestation of categories for words
Because of the size of the vocabulary and the frequency distribution of its items, some words will be completely missed in any corpus. Also missed will be particular uses of some words, and therefore some categorial ambiguities. That is, some words will occur which can undoubtedly represent more categories than are attested.
First, there are many hapax legomena, word forms which occur only once within a given corpus. In the Brown Corpus, about 45% of types, comprising 2% of all tokens, are hapax legomena; in the Greek New Testament, the respective figures are 57% and 8%. However ambiguous some of these words may be, their ambiguity cannot be established on the basis of these corpora. A spot-check of the hapax legomena listed in Kučera and Francis (1967) revealed many forms which are intuitively ambiguous. Specifically, there is a significant number of -ed forms, many of which can be either VBD (past tense verb) or VBN (past participle); and -ing forms (e.g. tracing
), which can be either VBG (present participle/gerund) or sometimes NN (noun).
Second, words which only rarely represent a secondary category may appear to be unambiguous despite multiple occurrences. The word form time,
for example, occurs 1,567 times as a noun, but only once as a verb in the Brown Corpus (Francis and Kučera 1983[1982], p. 417; note that the various forms of the verbal lemma time
occur a total of 16 times).23.1 A different corpus might well have missed the verbal use of this base form entirely, making the word form seem unambiguous. Indeed it would seem quite reliably unambiguous, given so many instances as a noun. Nevertheless, the use of time
as a verb is not at all remarkable, being quite familiar to any native speaker, and also being listed in typical dictionaries. The American Heritage Dictionary even lists adjectival uses for time,
which are not attested in the Brown Corpus even once. The frequencies for the possible tags of a particular word form define Relative Tag Probabilities
, or RTPs
; these data will prove important for disambiguation.
Third, any word in English can be used as a proper noun, though function words are somewhat resistant to this derivation. A well-known humorous radio sketch plays on exactly this process, discussing a baseball team with players named Who,
What,
and so on.
Fourth, any word in English can be mentioned
rather than used, as in the word ‘this’ has four letters.
Lackowski (1963) discusses such metalinguistic uses as support for the claim that all categorial collocations are possible. This argument only holds if the mention of a word is tagged only with the word’s more general category of use; that approach seems undesirable. I would suggest, instead, that mention of a word is either a grammatical category in its own right, or perhaps is appropriately tagged as a noun. If this method is followed, then all words are ambiguous, being capable of use as this mention-category; but at least syntax need not be complicated by allowing every category to occur in certain characteristically nominal positions.
Tables 4 and 5 show the number of types and tokens for each degree of ambiguity, in the dictionaries which are based on the English and Greek corpora.24.1 As already mentioned, these figures are undoubtedly well below the true figures for both languages, but they do give some idea of the relative prevalence of ambiguous words of varying degrees.
|
|
Collocations of categories
The disambiguation algorithms which I investigate depend upon a knowledge of the probabilities with which pairs of categories co-occur. As with words and categories for words, particular ordered pairs of categories may not be attested in a particular corpus used for normalization. I discuss later the rate at which categories are discovered (in terms of the size of corpus used for normalization), but no matter how large the base corpus it must be remembered that any or all of the remaining unattested collocations may be rare rather than impossible.
Overcoming sampling limitations
For this thesis I generally take the Brown Corpus as the universe of text for English, and the New Testament for Greek. This choice is a practical one; one cannot investigate everything, and in particular, tagging research requires tagged texts for normalization and measurement. This choice, however, has subtle effects on the tagging accuracy obtained.
First, the hapax legomena will always be tagged correctly if they are in the dictionary, whereas it is fair to assume that some of them are in fact ambiguous, and some instances of those would be missed by the disambiguation algorithm. This state of affairs must lead to a slight artificial increase in the accuracy found when using the normalization corpus also as the target text to be tagged. But since the hapax legomena constitute only 2% of all tokens, unless they would be drastically less accurate than other words their impact on total accuracy must be small.
Second, assuming that the hapax legomena are unambiguous will negatively affect accuracy on corpora other than the one on which the dictionary is based. This is because the program cannot know what categories unknown words may have, and so must make assumptions which are likely to be wrong more often than decisions based on more evidence. This is particularly true for word forms which the program finds in its dictionary, but without the correct tag for the novel instance.
Third, the presence of more ambiguous words will increase the mean length of contiguous spans of ambiguous words. This could slightly increase the running time of the disambiguation algorithm, but should only affect the accuracy in cases where the new ambiguity outweighs the cumulative effect of earlier decisions. I anticipate that these cases will be quite rare.
Finally, it is worth noting that the very definition of ambiguity here is stricter than usual; I do not consider semantic ambiguity per se at all. Also, I determine ambiguity on the basis of word forms, not of lemmas or form-sets; if all the categories represented by all the members of a form-set were included, ambiguity would of course be vastly higher.
On the other hand, the fact that many more words are in fact ambiguous than appear to be means that the task of disambiguation is harder than it appears. So the accuracy figures expected to be achievable with very simplistic methods (e.g. picking the favorite tag for each word without regard to context) must be reduced for unrestricted corpora. I discuss this further in the following section on measurement of accuracy, and later present related empirical data.
Several partial solutions to the problem of incomplete attestation of categorial ambiguities are possible:
First, one can use external information to expand the list of known tags for some words. For example, Church (1988) has expanded tag-lists initially built from a corpus, by extracting information from dictionaries; in my opinion this is an excellent approach. One can also scan additional tagged corpora if they are available, to similar effect.
The COBUILD dictionary project (Sinclair 1986[?]) has developed a dictionary using the reverse form of influence: categories and uses for word forms were discovered by retrieval of citations from a large collection of actual texts. Renouf (1984) describes this collection as containing 12 million words, updated with time; it includes many complete works, and a sub-corpus relevant to teaching English as a foreign language. A dictionary of this type might be particularly useful in revealing additional tags for a disambiguation dictionary.
Second, one can make rules for productive ambiguity. That is, one can assert that all word forms of a certain grammatical category may also represent another category (or categories). This appears to be too strong a step; even very widespread phenomena, such as the ability to verb nouns, are not entirely productive. First, many words resist non-morphological derivation, presumably because they allow derivation by affix, such as nominal
vs. nominalize.
Second, some words resist derivation because the potential derived use would duplicate a word already available, such as satisfy
vs. satisfaction.
Third, some lexical items either idiosyncratically or perhaps systematically resist derivation, such as names of roles, for example linguist.
In general, words which already have derivational affixes also have greater resistance to such derivation.
A third partial solution to the problem of incomplete attestation is to permit additional tags dynamically, when indicated by context. For example, an English word which is attested only as a verb, but which immediately follows an article, might be given the possibility of interpretation as a noun. The choice of tags to be added could be determined solely by collocational probabilities, or could be constrained by other rules of regularity.
I do not investigate these potential approaches in this thesis. However, I do investigate the effect of a limited initialization corpus in three ways:
First, I successively remove forms from the dictionary (in order of increasing frequency). Unknown words undergo no morphological analysis whatsoever; rather, they are assigned the most likely several tags based upon preceding context, and then disambiguated just as if they had been found in the dictionary.
Second, I divide the Brown Corpus in half and use each half as the basis for normalization. That is, a dictionary and probability tables are built based solely on a 500,000 word sample. Each normalization is then applied both to its own half and to the other half, which is in effect novel text.
Third, I have applied the tagger to an unrelated sample of text and checked the results by hand. This method is prone to human error, but is a valuable additional check nonetheless.
In examining unrestricted text, one is sure to encounter words not seen before, and some strategy must be employed for assigning tags to such neologisms. Although neologisms cannot be assigned grammatical categories as easily as known words, as Ryder and Walker (1982, p. 138) point out, speakers can construct syntactic analyses even for a text such as Jabberwocky, which contains a high proportion of such words. Thus the performance of any tagging method with an incomplete dictionary is of interest. These three control studies serve to investigate the algorithm’s robustness in the face of incomplete information.
Patterns of ambiguity
A specific pair of categories may co-occur either systematically (for all or virtually all word forms which have either) or idiosyncratically (for a highly restricted set of word forms). In English, many words may be coerced between uses as noun and as verb, and surely any word is potentially a proper noun. In Greek, certain categories are regularly ambiguous, such as genitive plural nouns. There are also words in both languages which uniquely exemplify a particular group of potential categories; many for English may be found in Appendix 4.
I will refer to the set of potential grammatical categories for a given word form as an ambiguity set. The Brown Corpus reveals 359 unique ambiguity sets (including the 88 sets of cardinality one, representing unambiguous words); they are listed in Appendix 4, sorted by type-frequency, by token-frequency, and by the tags included in each distinct set. The ambiguity set which has the most word types representing it is, perhaps not surprisingly, VBD (past-tense verb) vs. VBN (past participle); the most frequent major-class ambiguity set is NN (noun) vs. VB (present non-3rd-singular verb). Respectively, these ambiguity sets are denoted VBD/VBN
and NN/VB
.
A particular word instance represents not only the set of potential categories appropriate to its word form, but also a particular category appropriate to the specific instance. This combination of data is called a resolved ambiguity set.
30.1
For example, the word form flying
has the ambiguity set VBG/NN (present participle/gerund versus noun). But a particular instance of this word form, in which it functions as a noun, is an instance of the resolved ambiguity set denoted VBG/NN:NN,
where the second NN
specifies the current use.
Each ambiguity set can be resolved in as many ways as there are tags in the ambiguity set. For example, words of the ambiguity set VBD/VBN can be used either as VBD or as VBN, respectively representing the RASs VBD/VBN:VBD and VBD/VBN:VBN. The total number of resolved ambiguity sets is equal to the sum of the cardinalities of all the (un-resolved) ambiguity sets. The Brown Corpus reveals slightly over 900 such resolved ambiguity sets.
RASs are distinct from RTPs (Relative Tag Probabilities). The latter express information about specific word forms. The former express information about classes of word forms, where the forms in each class share the same set of potential categories. These classes are in general larger than individual lexical items, and smaller than grammatical categories per se.
Although use of RASs in the tagging algorithm for English results in particularly accurate tag assignment (see Chapter 4), I do not treat this as the preferred method. This is primarily because the number of potential RAS collocations is so numerous as to require impractical amounts of normalization text. Because of this, the high accuracy found may be an artifact, and should be verified with other corpora.
When necessary, I will refer to the more fundamental notion of a grammatical category label as an atomic tag
, as opposed to the set of tags constituting an ambiguity set. Tables in Appendixes 3 and 9 show, for each atomic tag, the number of word types which represent it, and the number of word tokens, in the Brown Corpus and in the Greek New Testament. A similar table, showing the number of tokens of each tag, broken down by genre in the Brown Corpus, appears in Francis and Kučera (1982).
Morphology and derivation
Many words can be categorized by their affixes. In a highly-inflected language such as Greek affixes generally determine the major category, and even the precise case and other information is identifiable, though with some ambiguity. Affixation in English is not so uniformly productive; yet a large set of affixes have been identified, which give fairly consistent evidence as to category (see Greene and Rubin 1971, Johansson and Jahr 1982, and Quirk et al. 1985).
As already mentioned, I will not be investigating techniques of morphological analysis. I adopt a stochastic approach to words not in the dictionary, choosing potential tags on the basis of context rather than form. This technique, being relatively untried, is of greater interest for this study than would be re-developing detailed affix lists. However, the handling of neologisms, by whatever method, is not my emphasis in this thesis.
Mathematical foundations31
A number of topics drawn from the fields of probability theory, statistics, and formal language theory are relevant to stochastic disambiguation methods. Some of the major results which underlie this method are presented here in brief form. More detailed presentations may be found in the cited literature. A later section describes the stochastic tagging method per se, building upon these mathematical foundations. Readers already familiar with stochastic methods in computational linguistics may wish to skip some of the discussion.
Conditional probability
The conditional probability of an event B is, intuitively, the probability that B will occur given that another event A has in fact occurred. It is generally written P(B|A), and is read the probability of B given A.
Since it is a probability, it is expressed as a real number in the range 0<=P(B|A)<=1; it is defined as the probability of co-occurrence of A and B divided by the independent probability of A (cf. Çinlar 1975, p. 14), that is
Equation 1: Conditional probability
This formula may (in effect) be reversed, in order to establish the total probability of B if the conditional probabilities of B with respect to enough other events are known. Enough
is formally defined as a set of independent events {A1, A2, . . .} whose probabilities sum to 1 (i.e., certainty). Then (Çinlar 1975, p. 15) the total probability of B is
Equation 2: Total probability
In this research two kinds of conditional probabilities will be used. First are those which express serial relationships between grammatical categories. For example, the probability of encountering a noun given a preceding article (written p(NN|AT)) is fairly high in English, while p(VB|AT) is very low. Second are those which express the relationships between grammatical categories and particular lexical items. For example, a particular word form such as chair
may occur frequently as a noun, and only infrequently as a verb. A complete table of the probabilities of tag pairs, based on the Brown Corpus, is found in Appendix 5; the distribution of tags for particular lexical items is reported in Francis and Kučera (1982), organized by lemmas rather than by word forms.
Markov modelling
Markov models
take a message to be a series of discrete units or symbols, each of which is a token of some type. The probability of a given type’s occurrence is taken to be a conditional probability, depending solely on the immediately preceding symbol. Miller and Chomsky (1963, p. 424) note that strictly speaking,
in a Markov model only the single, immediately preceding outcome
is relevant at each point. This strict definition is also used by Martin (1967, p. 5). One may view the last symbol as the state
of the model, and the next symbol as the probabilistically chosen transition
from that state. Thus, a Markov model can be translated into a finite state automaton (FSA
) with weighted arcs.
Such a model may be used either to generate
or to recognize
sequences of symbols. Symbol sequences, whether related to natural language or not, are called sentences.
In a Markov generator, the weight attached to each transition determines the conditional probability that the model will emit the symbol which the transition represents (as opposed to other possible symbols), given the model’s state, which is equivalent to the previously emitted symbol. Since exactly one transition must always be chosen (at least, this is so for the current purpose), the weights of all transitions from a given state add to 1.
A Markov recognizer is essentially the same, but the choice of transition at each step is governed by the next symbol actually occurring in the sequence to be recognized, rather than being randomly chosen. The weights then provide for measuring relative likelihoods of sentences, as shown in the example in the next section.34.1
Category models
In this investigation the symbols of interest are grammatical categories, and the conditional probabilities are called transitional or collocational probabilities. They describe sequences of categories. A Markov generator for categories would begin in a start state, and generate one of the possible sentence-initial categories (per se, not a word of the category), such as (for English) noun, pronoun, article, etc. Over a large number of trials, each category would be chosen in accordance with its likelihood in that context. This likelihood is determined by counting occurrences in a large pre-tagged sample of text.
Once the Markov model chooses a category, that category’s associated state becomes the current state of the model (replacing the previous state, such as sentence boundary). The process is then repeated, choosing the next category on the basis of the probabilities assigned for all categories possible after that state.
For example, Figure 1 shows a simple Markov generator for some English-like category sequences, and its associated collocational probability table. The name of the category generated by each transition (arc) is not shown, because it is the same as the name of the state at which the arc terminates. Note that many potential transitions are not shown at all; these have a probability of 0 in this particular generator, and are omitted for the sake of notational simplicity. For example, the generator shown can make no sequences corresponding to transitive sentences, because the only successor to verb is sentence-boundary. Output from this generator would include sequences like: ART ADJ ADJ N V, N V, etc. See Thomason (1986) for some other examples of probabilistic automata.
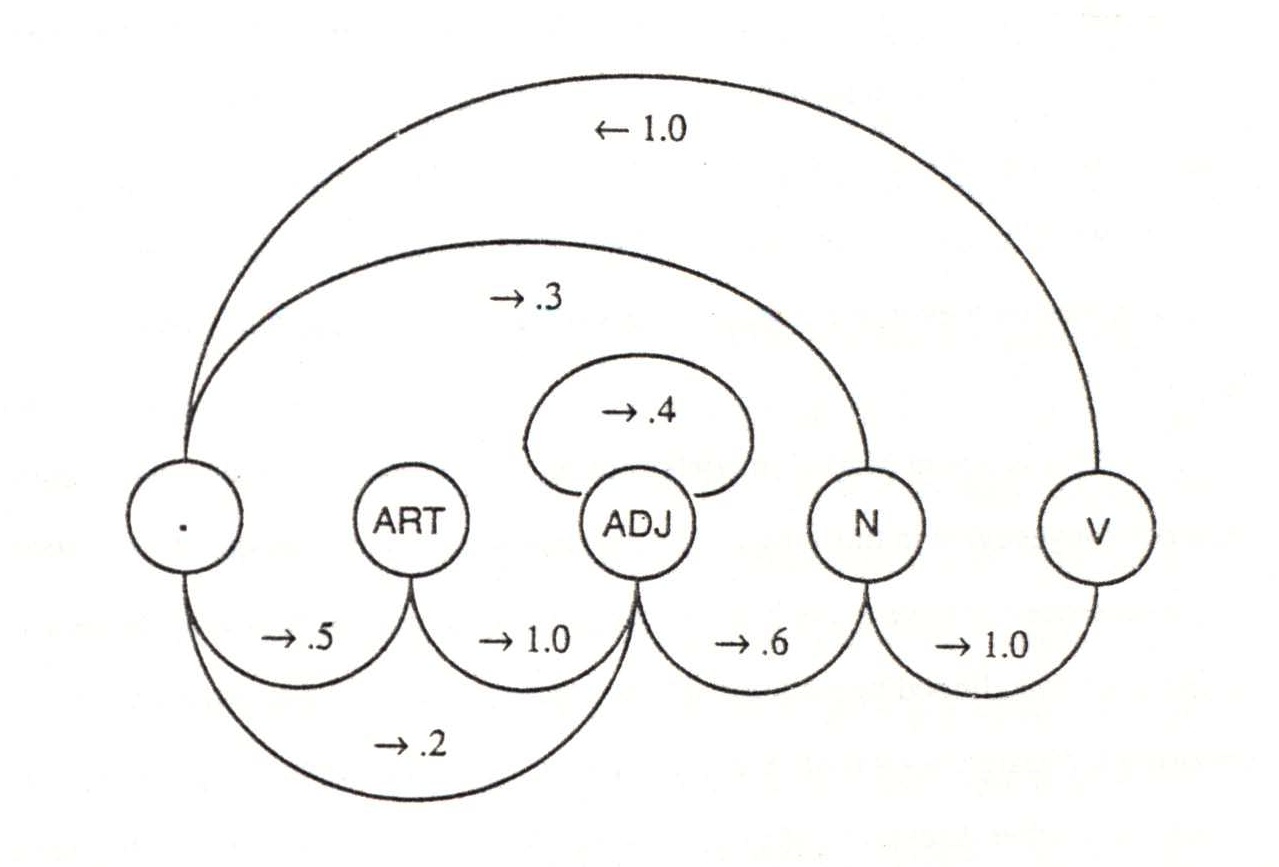 | |||||
| . | ART | ADJ | N | V | |
| . | 0 | .5 | .2 | .3 | 0 |
| ART | 0 | 0 | 1 | 0 | 0 |
| ADJ | 0 | 0 | .4 | .6 | 0 |
| N | 0 | 0 | 0 | 0 | 1 |
| V | 1 | 0 | 0 | 0 | 0 |
The model in Figure 1, if viewed as a Markov recognizer, can decide on the grammaticality of sequences. For if any of the missing (weight 0) transitions is necessary to match a particular sequence (as would happen immediately following the verb in a transitive sentence), then that sequence is ungrammatical under the given model.
The weights on the transitions, similarly, can be used to calculate a total likelihood for a sequence as it is recognized. The total likelihood is the product of all arc-weights encountered. This figure may not be intuitive, because it will be unmanageably small: the likelihoods of all sentences of a particular length will total 1.
Nevertheless, given two category sequences of equal length, the total likelihood of each is a measure of naturalness, or the frequency with which one would expect to actually encounter the sequence in a large set of sequences. Sequences with highly unlikely collocations of states (i.e., of categories) will have correspondingly low total likelihoods. Any sequence with even one impossible collocation will end up with a potential likelihood of 0.36.1
This is where Markov models connect most closely to the disambiguation methods I investigate in this thesis. The problem which categorial ambiguity raises is that a single sentence can have many possible tag sequences. A weighted Markov recognizer can assign a total likelihood to each possible tag sequence, and thus provide a basis for choosing the assignment(s) of categories to be used in later processing. See Lackowski (1963) for further discussion of grammars which generate sequences of categories, as opposed to those which generate sequences of lexical items.
Word models
No mention was made in the last section of how a Markov model might deal with words instead of grammatical categories. But since a Markov model concerns abstract symbols, one can simply substitute word forms for categories and apply the same methods.
A problem of scale quickly arises, however. The number of potential transitions is equal to the symbol vocabulary squared; for a useful subset of the set of English word forms this number is large enough to pose storage problems if the model is to be realized. A more crucial problem, however, is obtaining a representative sample, which provides adequate estimates of collocational probabilities.
Some pairs are very frequent, such as . The
or she said.
But most pairs are quite rare, and an impossibly large sample would be required to find them even once. Jelinek (1985, 1986) discusses this problem in detail, and develops mathematical models by which unknown values may be estimated. But even if a complete table were available, predicting collocational probabilities of words neglects the very linguistic regularities which grammatical categories are designed to reflect.
A simpler way to add word-level information to a Markov generator would be to add a lexical-insertion device, which chooses an appropriate word for each category instance generated by the model. Words would be chosen on the basis of probabilities (either of the word taken in isolation, or given the categorial context). The resulting device could generate sentences with some of the characteristics of natural language.
A corresponding way to add word level information to a Markov recognizer would be to add a device which substituted categories for words, and then gave its result to the category recognizer already described. This substitution device is merely a dictionary.
Because several categories may be possible for a given word, a large number of category sequences must (conceptually) be tested for a given sentence. This could be accomplished by exhaustive testing and comparison. That is, all combinations of assignments of categories to a sequence of words could be generated, and each category sequence could be evaluated by the FSA. But because each choice has only localized consequences, a more efficient method is possible. Martin (1967), van Hee (1978), and van der Wal (1981) discuss the relationship of Markov models and dynamic programming from several perspectives, but for my purposes it suffices to note that one can find the sequence of highest likelihood without exhaustive search.
Extended Markov models
One may extend the Markov modelling framework by defining successive orders of approximation,
which take into account greater amounts of prior context. Ideally, the probability assigned by a language model to any word [or similarly, any category] should depend on the entire past sequence. . . . However, it is practically impossible to implement such a dependence. . .
Jelinek (1986?, p. 1). Thus, realizable models must limit the amount of preceding text which affects each categorial or other lexical decision.
A zero order approximation
38.1 does not take into account any probabilities. All symbols are considered equiprobable, and context is disregarded.
A first order approximation
takes each event as isolated; its probability is related to no preceding events. Each symbol has its own probability based on frequency of occurrence. In the category sequence generator discussed above, this corresponds to generating the correct proportion of each category, but with no constraints on order or collocation. In other words, the weights of corresponding arcs match regardless of their origin state, or (equivalently), the model can be simplified to having one state, with one weighted arc per symbol.
In tagging, this approximation is being used if each word token is simply assigned the most frequent tag known. One may pick the most frequent tag overall, but this is a poor strategy. This approach for the Brown Corpus would result in all words being tagged as NN (noun, 13,359 types, 165,265 tokens). This would give an accuracy of less than 20% (cf Francis and Kučera 1982, pp. 533-543). In the Greek New Testament, the tag with the most types is N-AF-S (accusative feminine singular noun, 638 types, 2,873 tokens), and the tag with the most tokens is CC (co-ordinating conjunction, 30 types, 11,159 tokens). Tagging everything as CC would result in an accuracy of under 8%.
Alternatively, one may pick the most frequent tag known for each word form. This is obviously a much better strategy. This approach for the Brown Corpus would give an accuracy of about 93%; for the Greek New Testament, about 90%.
A second order approximation makes use of the relationship between pairs of adjacent events. That is, the probability of a particular event depends not only on the event, but on one preceding event. This approximation uses data such as the fact that an article is much more likely to precede a noun than to precede a verb. For a vocabulary of n symbols, the corresponding FSA would have n states (one per vocabulary symbol), with up to n weighted arcs from each state (for n2 arcs altogether).39.1 The probability data thus form a convenient table, reading down for the current state, and across for the possible successor. This is the usual Markov modelling approach, and the one with which I am primarily concerned.
A third order approximation adds knowledge of triplets of events; say, that article/adjective/noun is more likely than article/adjective/adjective; it thus requires an FSA of n2 states, with up to n3 arcs. Each state corresponds to the sequence of the last 2 symbols generated.
Higher orders are defined in the obvious fashion. I will deal only with zero, first, and second order approximations. Church (1988) presents similar work with third order approximations. Jelinek (1986) uses third order approximations in a different application.
Zipf’s law
Zipf’s law (Zipf 1935, 1949) describes the relationship between the frequency of events, and the rank of those events when ordered by frequency. It states that the item with rank n will occur 1/n times as often as the item with rank 1. That is, that the probability of the item at rank n is distributed as p(n) α r-1. This relationship is commonly displayed on a graph with logarithmically scaled axes, on which it is a straight line with slope -1. Zipf also observed that word length is inversely proportional to word frequency in several languages, and that the number of word forms of a given frequency is inversely proportional to the square of that frequency (Zipf 1935, pp. 23-48).
The Zipf relationship, though not a law
in the formal sense, is found repeatedly in the examination of lexicostatistical data. The most common example is the frequency of word types in a corpus, versus the rank of those same types when ordered by frequency. Mandelbrot (1961, p. 190) notes that the relationship was discovered by Estoup (1916) and Willis (1922[1924]); another early presentation is Condon (1928), based on two separate 100,000 word samples of English. Similar examples can be found in the distribution of word lengths, sentence lengths, and other phenomena. In general, the relationship holds less accurately at the extreme ends of its domain; certainly at the low end this is to be expected due to sampling error.
Zipf claimed that this law applies not only to linguistic phenomena, but to social phenomena as well. Indeed, the title of one of Zipf’s works, The Psychobiology of Language (1935), shows the breadth of application intended. He also acknowledged that in some cases the slope of the relationship is other than -1 (Zipf 1949, pp. 129-132), a modification also pointed out as necessary by Yule (1944, p. 55), Mandelbrot (1961), and others.
However debatable some of Zipf’s particular claims may be, in the domain of lexicostatistics the relationship of frequency and rank is thoroughly attested. Miller and Newman suggest that there are few quantitative laws of human behavior that have such a broad range of application
(1958, p. 209).
Miller and Chomsky give an account of the relation between word length and frequency purely in terms of probability (1963, pp. 456-464). Specifically, assume that symbols (e.g. letters) occur with certain independent probabilities. Assume further that the constituent boundary (e.g. word-space) is merely another such symbol, with its own (presumably high) independent probability. A Zipfian relation of word length vs. frequency is then predicted. This is because after each symbol there is another chance to generate the boundary symbol, making its probability of having occurred to be a monotonically increasing function of the number of symbols since its last appearance; therefore the probabilities of words of greater length (i.e., longer sequences which entirely omit the boundary symbol) are lower than the probabilities of shorter words.
If this analysis is accurate, then there is little to set space
apart from the other symbols, and it should be the case that the same length-frequency and rank-frequency relationships hold if a different high-frequency symbol (such as e
) is treated as the separator, with a word
then being defined as the sequence of characters between successive instances of the newly chosen separator character. Miller and Newman (1958) examined this hypothesis. They had a computer count words
in a sample 36,253 words long, defining several different letters as the space
character. They found that although the function relating [frequency to rank] is flatter [with
(p. 217) that is, a Zipfian relation.e
as space] than it is for words, it is still true that we have a roughly linear function on log-log coördinates,
Mandelbrot (1961, p. 192) predicted that a great deal of the original great interest in ‘Zipf’s laws’ is bound to be transferred to the examination of the possible discrepancies between the actually observed empirical facts and the predictions of the theories. This amounts to the examination of the validity of the markovian model used in this context.
However, this prediction seems not to have been fulfilled; relatively few discussions of the degree to which various linguistic phenomena are modelled by Zipf’s law are to be found. Also, although Zipf’s law has frequently been discussed in relation to word and letter counts, it has seldom been discussed at the more abstract level of grammatical category or collocational frequencies. I examine the distributions of these phenomena in a later chapter. Mandelbrot (1961) discusses data which suggest that a more accurate model for lexical phenomena differs from Zipf’s by having a greater exponent on r; that is, that p(i) α r-B, where B is a constant greater than 1. This prediction corresponds to a steeper slope of the log-log line. Some of the lexicostatistical properties I will present appear to be modelled best with values of B substantially greater than 1.
Because Zipf’s law describes an idealized distribution of type frequencies, it also predicts a value for the first order entropy of a source which produces that distribution. In a later chapter I derive this value and compare it to empirical values for Greek and English.
Entropy
Entropy is a measure of information content in a known message source. It describes the uncertainty involved in predicting successive symbols from an information source. Equivalently, it is a measure of the amount of information provided by each successive symbol (i.e., each selection precisely overcomes the corresponding uncertainty). Entropy may be measured in various units; the most common is the bit. More detailed introductions to entropy and related concepts of information theory may be found in Smith (1973) and Cherry (1957).
If all symbols of a given source vocabulary S are used equiprobably, the unpredictability of successive symbols is maximized. This results in maximum entropy, and may be denoted by F0 (Shannon 1950[?], p. 51) or Hmax (Kučera 1975, p. 127). It may be calculated as:
Equation 3: Maximum entropy
where |S| denotes the cardinality of the symbol set S. If the desired unit of measure is the bit, the logarithm is base 2.42.1 Since Hmax is a function of symbol set size, the actual entropy estimates found for sources with different vocabularies must be normalized before comparison (see below).
If the symbols in S are not equiprobable, then the entropy is lower, for the more frequent symbols are more predictable. If there are no dependencies between symbols, then the source can be modelled precisely by a standard Markov model; the source’s entropy (which must be less than Hmax) is then given by:
Equation 4: First order entropy
If the source actually has dependencies between symbols, then H1 is only a first order approximation to the entropy. Higher order approximations can be calculated by taking into account the relative probabilities of larger sequences.
Let v be a member of the symbol vocabulary V, and s be a member of the set S of all states. Let p(v|s) be the probability of a particular next symbol v given the model’s state, which is the n-1 symbol context. Equally, p(v|s) is the probability of a complete n-gram. Let p(s) be the total probability of the state s, or, equally, the probability of the n-1-gram which s represents. Then the n order entropy is the average of the entropies calculated for all states, weighted by the probabilities of the states. Rewriting Equation 4, we then have:
Equation 5: n order entropy
Entropy as just described is incommensurable across varying numbers of potential symbols. However the relative entropy Hrel may be calculated as H/Hmax; this value is generally expressed as a percentage, and is commensurable despite varying vocabulary size.
Redundancy is defined as 1-Hrel, and is generally denoted simply as R. It measures non-entropy, or that part of the message which is theoretically predictable, or redundant.
For my purposes, redundancy (or its inverse, entropy) is a rough measure of the degree to which transitional probabilities will be useful in disambiguation. If all successors are comparably probable (a situation of high entropy), the context does not help in disambiguation. But if the preceding categorial context strongly predicts the category of the following word (a situation of low entropy), then one can more reliably choose from among potential categories for that word.
Entropy figures have been obtained for a wide variety of languages. Cover and King (1978) provide an extensive bibliography of such studies, including work on Arabic, Armenian, Czech, English, French, German, Italian, Kannada, Rumanian, Russian, Swedish, Tamil, Tartar, Telugu, and other languages. They also refer to a variety of studies considering other phenomena than normal language, for example aphasic speech, digitized images, and so on.
Ergodicity
Stochastic analyses in general require that a process have the property of ergodicity. A system is said to be ergodic if it is well-behaved with respect to its Markov probabilities. That is, an ergodic Markov generator must satisfy the condition that it can be counted on to produce a statistically typical output. This property is very similar to the more familiar requirement of continuity in calculus, which in effect rules out functions which have sudden changes (discontinuities
) at particular points.
Hockett (1953, p. 73) states that for a Markov chain to be ergodic the probabilities must be such that there is no state which can never recur.
Ergodicity is described in somewhat more detail in Shannon (1973[?], p. 8). Non-ergodic sources are unusual; Abramson gives the following example (1963, pp. 23-24):
The reference to Shannon (1973) is erroneous; it should be to one of the other works by Shannon in the Bibliography. Sorry!
Consider a second-order Markov source with the binary source alphabet S = {0,1}. We assume the conditional symbol probabilities
P(0|00) = P(1|11) = 1.0
P(1|00) = P(0|11) = 0.0
P(0|01) = P(0|10) = P(1|01) = P(1|10) = 0.5
. . .we have four states — 00, 01, 10, 11 [with transitions such that the source is always in the state whose name matches the last 2 symbols generated;] if we ever arrive at either state 00 or 11, we stay in that state forever.
Abramson’s example will, over many independent trials, produce 0’s and 1’s with equal probability. However, on a single long trial, it will surely end up producing either all 0’s or all 1’s. This is a non-ergodic source.
I will, for the purposes of grammatical disambiguation, approximate natural language by ergodic Markov models. Certainly there are linguistic phenomena for which such models do not account, but the accuracy of the model is a measure of the degree to which an account of those phenomena is required for successful natural language processing. As for ergodicity, certainly no grammatical category can, by its occurrence, prevent another category from ever occurring again, particularly since sentence boundary is treated as a category like any other.
Stochastic methods45
The stochastic methods of disambiguation which I investigate here are based on the notion that certain sequences of categories are more likely than others; i.e., that the categorial structure of natural language sentences can be usefully approximated by Markov models. A Markov model for this categorial structure can be defined in terms of a function which determines the probability of various potential tag assignments for each word. Once defined, that model can be applied in order to tag a corpus of natural language data, by assigning the most probable category in each instance of ambiguity. This gives a way to measure the accuracy of the model, which may then be revised to better reflect the properties of the natural language (at least insofar as those properties are reflected in the corpora being examined).
The ambiguities contained within a span of ambiguous words define a precise number of potential assignments of tags to all the words within the span. Each such assignment of tags is called a path. For example, the phrase still waters run deep
has 168 (7*2*4*3) paths, or potential tag assignments.46.1
Each path is composed of a number of tag collocations, and each such collocation has a probability which may be empirically estimated. One may then approximate each path’s probability by the product of the probabilities of all its collocations. The set of all paths for a span constitutes a span network,46.2
and the maximal probability traversal of this network may be taken to contain the best
tags.
The term trellis
has since come to be used for what I here call a span network
.
The advantages of this approach are several:
First, there is no theoretical limit on the length of span which can be handled. Although some earlier researchers have minimized the importance of long spans (see below), they arise frequently enough to be significant when dealing with large corpora.
Second, a precise mathematical definition is possible for this method of disambiguation. Subjectively determined rules, descriptions, and exception dictionaries may be entirely avoided.
Third, the method is quantitative rather than artificially discrete. Various tests and frames employed by non-stochastic disambiguation algorithms have, on the other hand, enforced absolute constraints on particular tags or collocations of tags.
Finally, it is both fast and accurate, and remains so even in cases of ungrammaticality.
The particular choice of a Markov model and its probabilities may be varied along many axes; specifically, the model may take into account varying orders of approximation in determining collocational probabilities, may include lexical-item-specific tag probabilities and other known characteristics of the data, and may combine the data it uses in varying ways. Such choices and their interactions have consequences for the total expected tagging accuracy.
General principles of stochastic disambiguation
The fundamental principle of stochastic disambiguation is that alternative sequences of tag assignments to words may be effectively evaluated based on the combined probabilities of their component assignments. In turn, the component probabilities are established by particular local categorial and lexical events, i.e. words and tags, which can be modelled by Markov models whose transition weights are estimated by sampling from tagged natural language corpora.
Consider a particular sequence of tag assignments; that is, a choice of tag for each word within a sentence or other group of n words. Let the probability of each particular tag assignment for the ith word (however it may be determined) be denoted pi. Then the total probability of the sequence is simply the product of all pi:
Equation 6: Probability of a tag assignment sequence
The problem of course remains of how one may best determine the value of pi at each word. I will consider only 2 kinds of information for this purpose. The first is the collocational probability of the tag being considered, given the tag of the immediately preceding word. This will be denoted CP. In the event that there is more than one tag being considered for the preceding word, all possibilities are considered separately. The second is the relative probability of the tag being considered, given the word to which it would be assigned. This will be denoted RTP.
The third element which determines pi is the function by which CP and RTP are combined. I will consider only their linear combination, using a variable weighting factor W. The weighting factor serves to shift the emphasis between CP and RTP, making one or the other a more significant factor in the evaluation process. The probability for a tag at a given location is then
Equation 7: General tag probability function
It is worth noting that this modification results in the probabilities for the several possible tags of a word no longer adding to 1; that is to say, the weighted probabilities only have relative validity. This has no untoward consequences if the tags are compared only to each other. If for some reason it were to become desirable to compare probabilities across words or in some uncontrolled context, then it would be necessary to scale the weighted probabilities such that they once again add to 1.
Other information could be included (in addition to CP and RTP), such as the probability of a tag given particular preceding word(s) rather than preceding tag(s); the probability of a tag given other potential tags for the same word; and many other factors. I will consider only CP and RTP.
Dynamic programming
The most obvious means of finding the optimal traversal of the non-deterministic stochastic automaton which constitutes the disambiguator is to traverse all paths, calculating the probability of each, and then sorting or comparing all results by total probability. This method requires excessively large time and space. Dynamic programming methods (see Dano 1975, Dreyfus and Law 1977), however, provide a solution which operates in time directly proportional to the length of the text to be tagged, as discussed in DeRose (1988).
Statistical normalization
The entire process of stochastic disambiguation presumes that the conditional probabilities of particular grammatical events are known. Native speaker intuitions may be able to provide some clue to the characteristics of such probabilities, but are notoriously imprecise. For this and other reasons a corpus-based approach is generally used to derive estimates for the required probabilities.
I will refer to the process of examining a corpus to derive estimates for the frequencies of grammatical events as normalization. The corpus so used is then a normalization corpus. Any corpus which is then investigated, based on information or hypotheses derived from a normalization corpus, is called a target corpus.
The central question in choosing a normalization corpus for a particular purpose is whether it is large enough. Closely related is the question of whether the corpus is representative; for example, a corpus in one dialect may not provide effective normalization for use with target corpora in another dialect. Corpora based on sub-languages (such as scientific English) pose analogous problems. Card and McDavid (1966) have compared the rank-ordering of the most frequent words in 4 diverse corpora; they note a number of interesting differences, and that the farther down the list one goes, the greater the discrepancies in the rank orders
(p. 599).
The Brown Corpus, being distributed across many genres and authors, should provide reasonable control for genre differences. In the next section I describe certain investigations of the effect of choosing a particular normalization corpus. However, this effect cannot be quantified without reference to additional tagged corpora.
The size of corpus required for establishing the transitional probabilities of the set of English grammatical categories I am using is not obvious. In a later chapter I derive some estimates for this requirement, based both on observations of certain properties of subsets of the Brown Corpus, and on theoretical extrapolations related to Zipf’s law. In short, the million words of the Brown Corpus do appear to suffice for the grammatical phenomena I am investigating; the same cannot be said of the 140,00 words of the New Testament for Greek, largely because Greek uses a much larger set of categories.
Measurement of accuracy
A key feature of any natural language processing system is the accuracy with which it deals with its input. The measurement of accuracy is therefore a major concern of this thesis, and in this section I will present the rationale underlying my approach to this problem.
Given a text which has been annotated by a grammatical categorization system, the obvious definition of accuracy is simply as the percentage of word tokens in that target text which were tagged correctly. But this definition presupposes a basis for comparison, i.e., that the correct
tag for each token is known, which is only the case in very specialized circumstances. Two other difficulties also arise when attempting to measure accuracy. First, not all errors need carry equal weight. For example, whether a word which lies between an article and a noun is tagged as an adjective or as a noun may be of no significance to later processing. Second, using the total percentage of correct tokens does not make plain the fact that many words are unambiguous to begin with (or are so rarely used in secondary categories as to be so for practical purposes). Getting these words right is not a surprising accomplishment, and a stricter scale should be kept in mind.
Alternative bases
There are at least three different bases for comparison which may be applied when deciding which decisions of a disambiguation algorithm are correct. They are (a) an alternative tagging algorithm, (b) native speaker intuition, and (c) using a standard tagged text as the target document.51.1
Alternative (a) may be quickly disposed of. To serve as a standard of comparison, the alternative algorithm must be highly accurate; at the very least, it must be significantly more accurate than the algorithm being evaluated. To my knowledge no non-stochastic tagging method has been proven as accurate on a wide range of text as the class of methods under consideration. Sampson (1987a, p. 21) concurs, describing the performance of the CLAWS algorithm, a stochastic method very similar to that examined in this thesis: We are unaware of any non-probabilistic system that comes close to matching this performance.
Alternative (a) may prove useful in the future, however, in comparing the particular errors made by different methods. If those errors are not largely the same, then two methods might usefully be combined to achieve a greater accuracy than either method alone.
Alternative (b), native speaker intuition, might have the apparent advantage of unquestionable accuracy. However, a number of pitfalls await the unwary. First, expert native speakers are required, because an average speaker’s knowledge of grammatical categories is largely tacit. Second, since any particular set of grammatical categories is the product of linguistic theory and analysis, different speakers may understand the range of use of particular tags differently.52.1
As Aarts and van den Heuvel point out (1982, p. 72) manual tagging, in whatever way it is done, is always to some extent unreliable.
The choice of tag set is in any case partly dictated by the purposes of the chooser, and various distinctions may not be clear to others, even experts. Third, even a single native speaker is not guaranteed to make consistent judgements, particularly after making many judgements. Fourth, this alternative is very time-consuming, and quickly leads to fatigue and mistakes.
Alternative (c), using a standard tagged text as the target, is accomplished by ignoring the target’s pre-defined tags, re-tagging it, and then comparing the pre-defined and new tags for each word. This alternative has a number of advantages, and is the preferred method. First, comparison is a rapid and perfectly repeatable computation; there are no distortions due to fatigue, idiolect differences, different understandings of how tags are used, etc. Ultimately the tags in a standard text are assigned by one of the other methods, but their elevation to being standard generally reflects the achievement of a significant consensus. Even if that were not true to begin with, any widely-used tagged text inherently invites correction of whatever errors it may contain.
Alternative weighting
For a given purpose, it may be that errors of certain kinds are particularly significant. One might, for example, choose to consider major class errors more detrimental than minor category errors. An instance of that
which is actually an objective wh-pronoun, might be considered only slightly off if tagged as a subjective wh-pronoun, but quite significantly off if tagged as a qualifier. Similarly, noun vs. adjective errors might be considered less significant than tense errors on verbs. In an inflected language, errors solely of (say) gender or number might be considered relatively insignificant. Various alternative weighted accuracies such as this could be calculated; I have not investigated this range of methods.
Alternative scales
The fact that many word forms are either unambiguous, or only slightly ambiguous (i.e., they almost always represent one category), means that any disambiguation algorithm with a good dictionary can get many tokens right with little effort. Since (based on the Brown Corpus) approximately 48% of the tokens in an English text are categorially ambiguous, even an algorithm which errs on every disambiguation will still show an accuracy of about 52% (if it has a complete dictionary).
A very simple method which does far better is to choose, for every token of each type, the most likely tag known for the type. This method is entirely ineffective for words not known to the tagging system on the basis of its previous normalization. But in the optimal case where the dictionary is complete (such as when the normalization and target corpora are the same), quite high accuracy can be achieved. For example, for the Brown Corpus this method produces an astonishing 93% accuracy. If we take this percentage for granted, then the percentage of the remaining hard
cases tagged correctly is lower than the total accuracy figures conventionally cited, as shown in Table 6 below.
It is important to emphasize that such high accuracy can only be expected when the normalization dictionary is complete. This will not be the case when the target document is unrestricted, although because of Zipf’s law practical dictionaries can achieve high coverage. While the chance of guessing the most popular tag for an entirely known word is quite small if context is ignored, contextual probabilities remain far more effective.
| Total Accuracy | Accuracy on hard cases |
| 94% | 23% |
| 95% | 36% |
| 96% | 56% |
| 97% | 62% |
| 98% | 74% |
| 99% | 87% |
Suffix analysis can help considerably in cases of unknown words, but is not an approach I investigate in this thesis. Interested readers may consult Garside and Leech (1982) for a detailed discussion of suffix processing in the CLAWS system, and for a table of suffixes and their associated tags. Greene and Rubin (1971), Kelly and Stone (1975), Johansson and Jahr (1982), and Beale (1987[1985]) also discuss affix analysis in tagging systems.
Choice of method
In this thesis I will measure accuracy using standard tagged corpora as targets. For English I will use the Brown Corpus, and for Greek, the New Testament as tagged by Friberg and Friberg (1981a, 1981b). Using these standard corpora gains the advantages discussed above over native-speaker or alternative algorithm checks, and several other advantages. However, these target corpora are the same ones which are used for normalization, and therefore it is more difficult to generalize results to the domain of entirely unrestricted text. For brevity, I will refer to accuracy measurement carried out by re-tagging the original normalization corpus as being isometric. In this section I will discuss the possible effects of isometric disambiguation as opposed to disambiguation of unrestricted target text, and preview investigations I have conducted to help control for the effects.
The main reason for this choice of target documents is that other comparable tagged corpora are not available. The nearest candidate would be the LOB Corpus, but it uses a somewhat different set of tags from the Brown Corpus, and is composed of British English texts, which are structurally different from the American English texts of the Brown Corpus to an unknown extent.55.1
Isometric disambiguation can be expected to have somewhat higher accuracies than might be found for unrestricted text. This is useful because it places an upper bound on the accuracy expected for the algorithm, while any particular nonisometric test may be either better or worse than average, requiring that a great deal of text be tested. In fact it is possible for a nonisometric accuracy measurement to exceed the isometrically predicted figure, but it is highly unlikely.
There are several reasons that higher accuracy is expected in the isometric case. First, a dictionary built by examination of a normalization text can be complete with respect to the same text, but will almost certainly be incomplete with respect to a substantial unexamined text. This entails that there need be no cases in which a word is totally unknown, for which the algorithm must assign a tag ex nihilo. This is an advantage because knowing all the words controls for the effect of affix analysis. Affix analysis is the standard method for assigning a tag or tags to unknown words, but lists of affixes and methods of matching them to words vary greatly and consequently can be expected to contribute varying amounts to the accuracy of taggers which use them.
Second, isometric application of a transitional probability table can be unexpectedly effective. Any collocations which occur only once will have been recorded idiosyncratically. This does not guarantee that they will be correctly tagged; for example if the sequence AT/UH (article/interjection) occurs rarely, and a word occurs which could be either an interjection or a noun, then it probably will be tagged as a noun in all cases. Nevertheless, idiosyncratic knowledge may help in particular cases where it ought not, such as when two alternative low-frequency collocations are in fact possible, but the second does not happen to occur in the normalization corpus. In that case the instances of the first will be tagged correctly both in the isometric case and the unrestricted case, even though any instances of the second in unrestricted text would likely be missed.
I have carried out several investigations which help to quantify any isometric enhancement of accuracy. They include:
- (a) Estimating the degree to which the transitional probability tables based on the normalization corpora I have chosen represent their languages in general.
- (b) Dividing the Brown Corpus into two entirely separate halves, carrying out separate normalizations based on the halves, and then tagging both halves ipsilaterally and contralaterally. This is particularly effective, because the contralateral portion of the Corpus is comparably tagged but entirely unknown to the normalized tagger, and because any effect can be measured symmetrically, controlling for the possibility that either half of the corpus provides a more effective normalization. Also, the fact that the normalization corpora are one-half the size of the Brown Corpus should make them, if anything, somewhat less adequate; because of this the contralateral accuracy should place a lower bound on the accuracy to be expected for unrestricted text. And third, this investigation controls for both collocational and relative probability effects.
- (c) Tagging (nonisometrically) a sample of newspaper text, and hand-checking it. This method is subject to the limitations described above for native speaker intuitions, but does provide an entirely independent check.
Several other methods of controlling for the isometric disambiguation effect are possible, such as generating an entirely new standard tagged corpus, or arranging to obtain the consensus of a group of expert native speakers. These methods are in general time-consuming and prohibitively expensive, and hence have not been pursued. One interesting future investigation would be to apply the tagger to the LOB Corpus. Before this were possible the LOB and Brown tag sets would have to be reconciled, for example by converting either corpus to the other’s tagging prior to normalization. Also, this comparison might or might not accurately reflect the effectiveness to be expected for a tagger within its own dialect, and so would suggest that other controls also be applied.
Next: Previous research