DeRose, Steven J. 1990.
Stochastic Methods for Resolution of Grammatical Category Ambiguity in Inflected and Uninflected Languages.
Ph.D. Dissertation. Providence, RI: Brown University Department of Cognitive and Linguistic Sciences.
This chapter originally began on page 86.
I have investigated some properties of stochastic tagging algorithms for English and Greek via a program which can assign tags to the words of a target corpus and compare each assigned tag to the actual tag provided in that corpus. This program reads the Brown Corpus or the Greek New Testament, a dictionary of words and their tag frequencies, and a table of transitional probabilities for tags. Other program modules derive these tables from a normalization corpus and maintain the data structures required for compact storage and efficient access of the data.
The disambiguation program, known as Volsunga, calculates the optimally-weighted assignment of tags for each sentence using a linear time dynamic programming algorithm. First, it looks up the set of possible tags for each word in the dictionary. Then for each word, it calculates the probability of each tag assignment, given (a) the possible tags of the current and preceding words (or, in the case of the sentence-initial word, the preceding sentence-boundary tag); and (b) the relative probabilities of the various tags given the word form. The sequence of tag assignments which has the highest cumulative probability is considered correct.
The program finally compares its own tag assignments to the actual Brown Corpus or Greek New Testament tags. Tag assignments which match are counted as correct; those which do not match, incorrect. Separate counts are maintained for several special categories of words. Specifically, contractions, punctuation-initial and digit-initial words, and words not listed in the program‘s dictionary are counted. For the Brown Corpus, so are words in headlines or titles, cited nouns, and foreign words (such classes of words are indicated by special affixes on their tags).
I applied the program to each corpus repeatedly, with incremental changes in the probability functions, and I analyze the results here, first for the more detailed studies conducted on the English data. I then present three studies which I conducted in order to control for the effect of isometric tagging (i.e., using the same text for normalization and as target), as opposed to tagging unrestricted text. For one configuration of the system applied to the Brown Corpus, I present the specific tagging errors which were made with their frequencies. Finally, I present a number of information theoretic results related to estimating the adequacy of normalization for stochastic systems. Some analogous investigations for Greek are also reported.
The transitional probability table includes all tag collocations which occur in the Brown Corpus. It is of size 882 or 7,744, or less than 1% of the Brown Corpus size. It is reasonable to expect that the million items counted provide sufficient evidence for the relative frequencies of these collocations; evidence for this is provided by the control studies reported below.
The word/tag/frequency dictionary contains 47,802 word forms. This is smaller than the total Brown Corpus vocabulary of 50,406 forms (cf Kučera and Francis 1967) because the dictionary omits word types which contain only digits and certain punctuation marks (specifically, the punctuation marks .,%$-/
). I took this step in order to conserve memory, allowing the program to run in reasonable space and time given that many applications of the programs to the entire Brown Corpus were required for later analysis. These particular forms were omitted because (a) many of them can be tagged with reasonable accuracy solely on the basis of the characters they contain, and (b) they tend to be very low in frequency, and so will have minimal effect on the end results.88.1
The types in the dictionary account for 961,704 tokens; Volsunga reports the total Corpus token count as 1,136,852. Thus about 14% of the Corpus tokens appear not to be accounted for by the dictionary. However, this includes period, hyphen, and comma, about which the program has independent knowledge. These 116,703 punctuation tokens88.2 constitute two thirds of the missing 175,148 tokens, leaving 58,445 tokens (5.14% of the total) which are unknown to the system.
I define the baseline accuracy as the percentage of tokens which a tagger would get right if it used the very simple algorithm of assigning the most popular tag for each type, to every token of that type. This is equivalent to setting the weight of collocational probabilities to 0%, and RTPs to 100%.
Atwell (1987, p. 58) characterizes this as the simplest possible likelihood formula,
and comments that is is likely to be quite successful. Svartvik and Eeg-Olofsson (1982, p. 102) applied essentially this method to the London - Lund Corpus of Spoken English, and report that this simple strategy is quite efficient.
Since the dictionary contains frequency counts broken down by tag, a baseline accuracy figure can be derived directly from the dictionary, without even using the tagging program. This is done by totalling the frequency counts for the most frequent tag for each word, and dividing by the total frequency of all tags for all words. The dictionary-based method gave a baseline accuracy of 92.17% for the Brown Corpus. Actually tagging the entire Brown Corpus gave a slightly higher accuracy, 93.10%.
There is a difference between these methods because the dictionary did not include numeric and punctuation word types. It is therefore apparent that numbers and punctuation marks have a higher baseline accuracy than other forms, which is not surprising. Punctuation tokens are not highly ambiguous. As for numeric tokens, to pose problems many of them would have to be ambiguous, and their alternative tags would have to be more uniform in their distribution than is true of other words, both of which are unlikely. Numbers (taken individually) tend to be quite rare, 89.3 and only a few tags are possible for them. Of 769 forms listed in Kučera and Francis (1967) beginning with the digit 1,
only 94 (12.2%) occur over 5 times, as opposed to 12,398 forms out of 50,406 (24.5%) for the Corpus in general. 467 (60.7%) are hapax legomena, as opposed to 44.72% of all forms in the Corpus, and of course all these forms are unambiguous with respect to the Corpus. A few of the remaining numeric forms might be ambiguous; for example 7 forms (out of 280 total) which can be used as cardinal numbers are categorially ambiguous; similarly, 7 of 114 ordinal forms are ambiguous (see Appendix 4).
Although the isometric baseline accuracy for the Brown Corpus was just over 93%, the baseline accuracy on unrestricted text was significantly lower. This is because (a) any limited corpus under-represents ambiguity, and (b) unknown words are harder to tag. Table 10 shows the baseline accuracy found isometrically, and that found by dividing the Brown Corpus in half, carrying out separate normalizations, and applying the tagger to each half, using each normalization. The unknown words reported in the ipsilateral cases are the omitted forms discussed above under General data,
such as numerals. For discussion of these procedures see Dividing the normalization corpus
below.
| Source | Target | Total Accuracy | Accuracy on Known Words | Accuracy on Unknown Words# |
| All | All | 93.135 | 92.877 | 96.593 |
| 1st half | 1st half | 93.324 | 93.128 | 95.966 |
| 1st half | 2nd half | 88.209 | 91.804 | 60.634 |
| 2nd half | 1st half | 87.358 | 91.943 | 55.081 |
| 2nd half | 2nd half | 93.323 | 93.028 | 97.239 |
As anticipated, it is evident that the baseline method of tagging did not generalize well to unrestricted text. The loss in accuracy was mainly on the unknown words, but was quite severe (compare these results to those reported below for varied dictionary sizes). Unknown words
were of two types: those excluded on the basis of form (e.g., numbers) and those occurring only in the contralateral portion of the Brown Corpus. The loss in accuracy on known words was small, and presumably a consequence of inadequate normalization in the contralateral cases. For example, a few words are likely to occur only with one tag within one half of the corpus, but with another tag or tags in the other half.
To my knowledge no non-stochastic tagging algorithm has demonstrated an accuracy significantly higher than even the contralateral baseline figures on a large body of real text. Klein and Simmons claim a slightly higher figure, but it was based on such a small sample and tag set that it should not be considered reliable.90.4 A nearly complete dictionary thus allows fairly accurate tag assignment, even without regard to context. This indicates that although ambiguity is widespread in the lexicon, ambiguous words tend to be strongly skewed toward a particular category.
For practical use, it must be remembered that high accuracy with this method requires knowledge of the most popular
tag for nearly every word to be encountered. This cannot be counted upon with unrestricted text, though it can be approximated to a high degree, given sufficient storage space and a large enough corpus for normalization.
Tagging can also be done using only collocational probabilities for tags, and entirely disregarding RTP information. This method is far less subject to problems with unknown words, because particular words are not a factor in tag assignment decisions. The dictionary serves only to constrain the set of potential tags for known words. Unknown words can merely be assumed to be highly ambiguous, permitting either (a) all tags or (b) all tags which label open classes. Both methods were tested in control studies reported below.
Tagging the Brown Corpus using only collocational information yielded a total accuracy of just over 92%. This is slightly lower than the accuracy obtained using RTP information alone. Table 11 shows the accuracy of this method in the full isometric, ipsilateral, and contralateral cases.
| Source | Target | Total Accuracy | Accuracy on Known Words | Accuracy on Unknown Words |
| All | All | 92.094 | 91.771 | 96.415 |
| 1st half | 1st half | 92.931 | 92.728 | 95.674 |
| 1st half | 2nd half | 89.522 | 91.386 | 75.224 |
| 2nd half | 1st half | 88.836 | 91.482 | 70.208 |
| 2nd half | 2nd half | 93.242 | 92.945 | 97.185 |
As predicted, this method was less affected by the difference between isometric and nonisometric choices of target text. The difference between the ipsilateral and contrateral accuracy figures was 3.9% with the collocational method, but 5.5% with the baseline method. The difference between the methods was even greater for the unknown words, although some errors on known words can arise because neighboring errors on unknown words bias the collocational probabilities.
Accuracy with Co-occurrence and Relative Tag Probabilities
Although either relative probabilities of particular tags for particular word-types or collocational probabilities may be used in isolation as a basis for assigning tags, it is also possible to combine both kinds of information. If the methods are not entirely redundant with respect to their disambiguation decisions, then more accurate tagging should be possible given their proper combination. As Graph 1 shows, this was found to be the case, and with the best choice of relative weighting a peak total accuracy of just over 95% was achieved.
In Graph 1 the horizontal axis represents a continuum from exclusive use of collocational information at the left, to exclusive use of relative tag probability information at the right. The vertical axis shows the corresponding accuracy obtained. Collocational probabilities CP values were calculated as the conditional probability of a successor tag, given a predecessor tag. RTP values were calculated as the probability of a tag, given the lexical item to which it was to be assigned. With w as the weighting factor used to shift between RTP and CP, the total probability function at each word was then, as shown above, the average of RTP and CP, weighted by w: (1-w)◊CP + w◊RTP.
It can easily be seen that optimal accuracy was obtained when RTPs were weighted at about 30-35%, versus 65-70% for collocational probabilities. If 93% accuracy is sufficient for a particular purpose, the user with a large dictionary may find it preferable to use the baseline method, as it is nearly trivial to implement; however, this method is less adequate for dealing with unknown words, and so for use with unrestricted text the extra effort to use collocational probabilities as well will in general be justified.
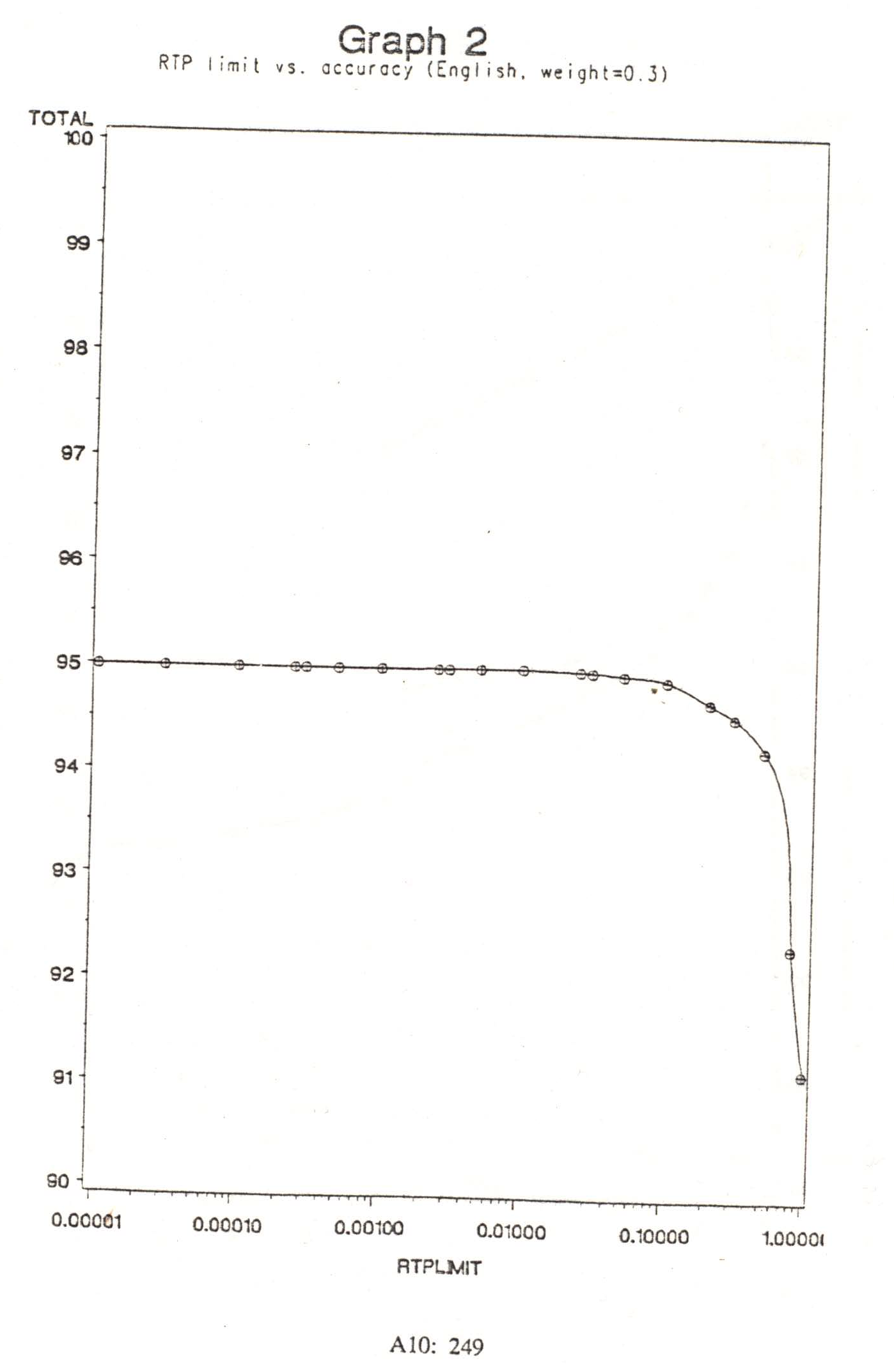
I also investigated whether given optimal weighting of RTPs, accuracy might be better with a limitation placed upon the magnitude of the RTP factor. For example, such a limitation could dictate that words which are more than 200 times more likely to be of one category than another (perhaps noun vs. verb), would still not contribute an RTP factor greater than 200, while smaller ratios would be untouched. This could have the effect of preventing RTPs from swamping collocational probabilities in extreme cases.
Graph 2 shows the effect of imposing such limitations, while retaining optimal weighting of RTPs. In fact there was virtually no effect upon accuracy until extreme limits were imposed, such as allowing no RTP ratio to exceed 10:1. After that the effect was predictably severe, since at a limit of 1:1 RTPs are by definition entirely ineffective, and the accuracy is therefore that of the collocational method in isolation.
The lack of effect for high cutoffs is due to the actual rarity of tokens which represent the secondary categories for their types. Assume the actual ratio for the tags of some two-way ambiguous word type is n:1. Then even if this ratio totally overshadowed collocational probability differences, thus forcing all tokens of the type to receive the more popular tag, only 1/n of the tokens would be tagged incorrectly. So for ratio limits much over 10:1, the maximum expected error rate would be much less than 10%, and hence would not harm the total accuracy.
It is reasonable to expect that by encoding finer distinctions between environments, higher accuracy might be achieved. Church (1988), for example, uses third order collocational probabilities as a means to improve disambiguation accuracy. But a danger with that method is that it is difficult to obtain an adequate tagged corpus for normalization. A third order collocational probability table for 88 tags has 883 or 681,472 cells, which is of the same order as the Brown Corpus size. A sufficient range of collocations would not be evidenced even by a normalization corpus several times the size of the Brown Corpus. See Graphs 15 and 16 (discussed below) for related projections regarding second order collocational probabilities.
In an attempt to increase the accuracy of tagging without resorting to third order statistics, I investigated the properties of resolved ambiguity sets. RASs, as discussed above under Patterns of ambiguity,
provide a more fine-grained subdivision of word categories than do atomic tags. I hoped that these finer distinctions would provide additional statistical discrimination useful to the task of disambiguation. This approach provided a substantial gain in accuracy, but is probably of limited applicability unless a larger normalization corpus is used.
As defined earlier, an ambiguity set is the set of tags possible for a given word form. Any instance of a word, then, represents a RAS, consisting of the set of tags possible for the word form, and the tag in use for the current word instance. If every word instance is taken to be tagged with a code identifying its RAS rather than only its current atomic tag, a new collocational probability table may be generated on this basis. The tagger may then use the new table for disambiguation.
In the Brown Corpus I found 359 ambiguity sets, which are listed with their frequencies of occurrence in Appendix 4. Generating the possible resolved ambiguity sets from this list yielded 911 resolved ambiguity sets and hence a table of 9112 or 829,921 potential collocations. The size of this table, particularly when combined with a large dictionary, poses a substantial though hardly insurmountable storage management challenge on many current computer systems. The corresponding atomic tag table, by comparison, requires only 882 or 7,744 entries.
To measure accuracy using RASs the algorithm proceeded as usual, but after looking each word up in the dictionary, it converted each of the tags to an RAS code. This was accomplished through a look-up table which was given the list of possible tags for the word, and, in turn, each of the tags in that list as a hypothesis. The table supplied a code number for each particular RAS, and these codes were used to access the specially-derived RAS collocational probability table. Thus, except for predicating collocational probabilities of a finer grained set of categories, this algorithm was identical to that already reported which combined CP and RTP.
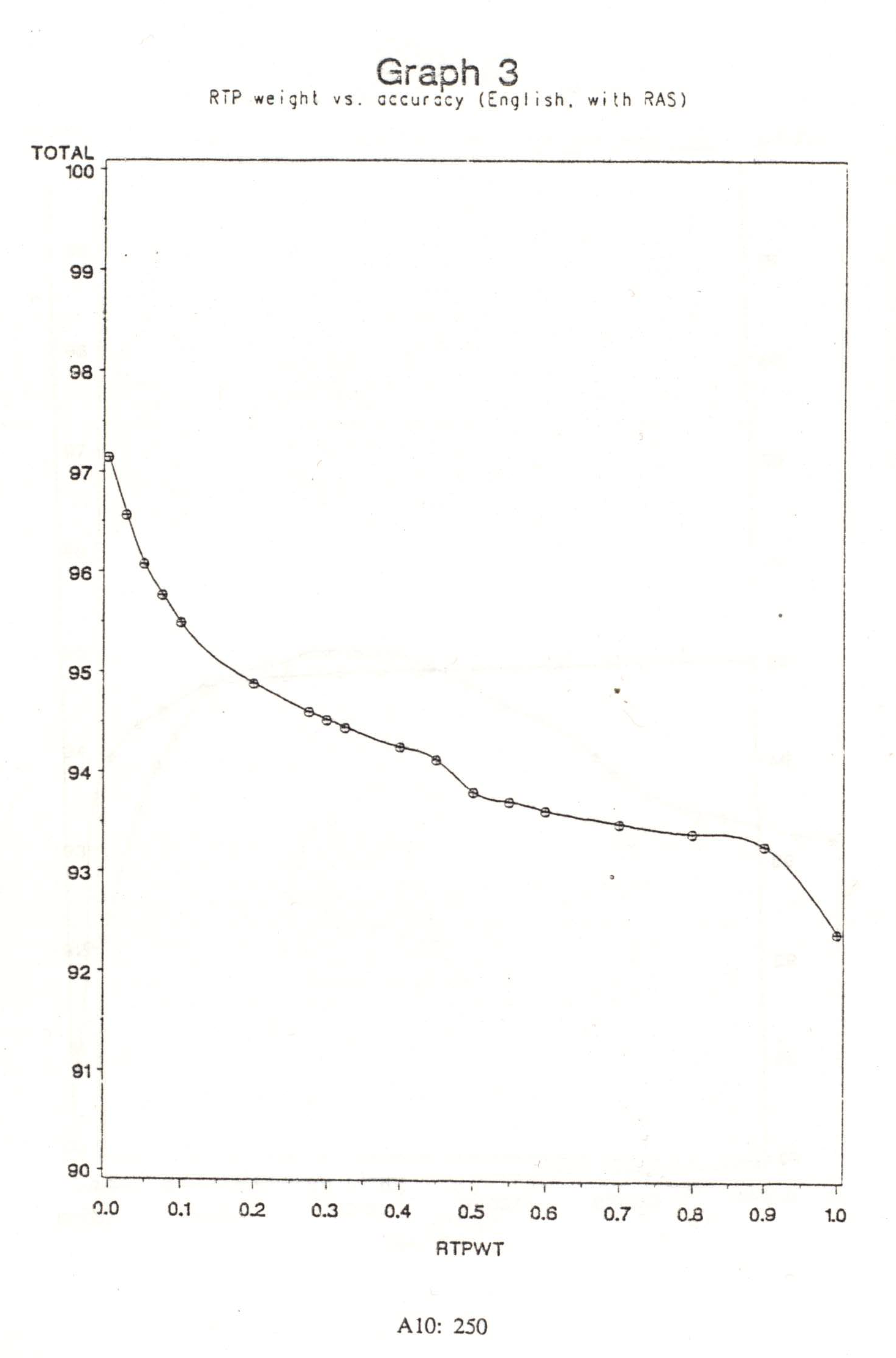
This method increased total accuracy by about 2.1%, to 97.14%. Put another way, it overcame about 40% of the residual errors. It also completely changed the pattern of the relationship between RTPs and collocational probabilities, as shown in Graph 3. With RASs, the optimum accuracy was achieved with 0% weighting for RTPs, that is, with RTP information totally ignored. Any increase in RTP weight produced a decrease in accuracy.
RASs most likely increased accuracy because they encode more information about the distribution of particular word forms, and of salient groups of word forms. For the many ambiguity sets which are represented only by one word type each, RTP information is expected to be redundant. This is because the RAS collocational probabilities describe the distribution of the various possible categories of those particular lexical items, and this is very similar to what RTPs describe. This explains the ineffectiveness of RTP weights when RASs were used.
Since Graph 3 is monotonically decreasing, it suggests the less than intuitive possibility that negative RTP weights would improve accuracy. If this were true (i.e., if the graph continued smoothly to the left of 0), then 100% accuracy would be expected at an RTP weight of about -10%. In fact, however, negative RTP weight severely decreased accuracy. Table 12 shows the effect of negative RTP weights on a small sample (37,948 tokens). There was a very steep drop to about 80% accuracy, after which greater negative weights had little effect.
| RTP weight | Total accuracy# |
| 0.0% | 96.34 |
| -0.1% | 92.81 |
| -0.5% | 86.98 |
| -2.5% | 79.82 |
| -5.0% | 78.44 |
| -10.0% | 78.28 |
| -50.0% | 80.91 |
| -100.0% | 80.40 |
The fact that using RASs increased the accuracy but obviated RTPs could indicate that words with the same ambiguity set correlate in terms of their RTPs. That is, words which are ambiguous in the same ways also tend to correlate in terms of the relative frequencies of their potential tags. This would in effect show that much of the information gained by distinguishing RASs as opposed merely to atomic tags, may be the same information which was expressed via the RTPs. The highest frequency ambiguity, NN vs. VB, would be expected to show this behavior simply on the grounds that NN is several times more frequent (overall) then VB. So unless the distribution of total tag frequencies for classes of ambiguous words is greatly different from that shown by unambiguous words, RASs and RTPs should correlate in the hypothesized manner. But it is also likely that the finer distinctions helped because they encode more cases entirely idiosyncratically.
In applying any disambiguation algorithm to unrestricted text, unknown words and tag collocations will arise, for which the algorithm has no prior information on which to base its decisions. On the other hand, tests on unrestricted texts pose problems for the measurement of accuracy, because there is generally no pre-existing tag data available to which the algorithm‘s performance can be compared. Geens (1984, p. 211) notes that any corpora to be used for statistical evaluations must be very large, lest the conclusions based upon them be restricted to the universe of the corpus itself.
This is particularly true when the number of distinct cases to be counted is large, as is the case with many Markov models. A key factor in the effectiveness of a stochastic disambiguation algorithm is thus the adequacy of its normalization corpus.
I therefore investigated the effect of normalization corpus size on accuracy in three ways. First, I made the dictionary ignorant of words of successively greater frequency. Second, I split the Corpus into two portions, and used the independent normalization derived from each half to tag the other half. And third, I tagged and then manually checked a sample of newspaper text unrelated to the Brown Corpus. All these methods provide information relevant to the algorithm‘s expected accuracy with nonisometric corpora, in which dictionary failures or collocational probability table inadequacies would more frequently arise. Studies of entropy as a function of normalization corpus size (reported in a later section) also bear on this issue, for if entropy has not reached a stable value by the end of the normalization corpus, it is likely that some important information has not yet been encoded in the probabilities.
In all the control experiments unknown words were assigned tags on the basis of context. First, all eligible tags were tested to determine the several best candidate tags, given (only) the possible tags of the preceding word. The sentence was then disambiguated as usual, treating the candidate tags previously chosen for each unknown word as the ambiguous possibilities for that word. Three variations on the method of choosing candidate tags were tried.
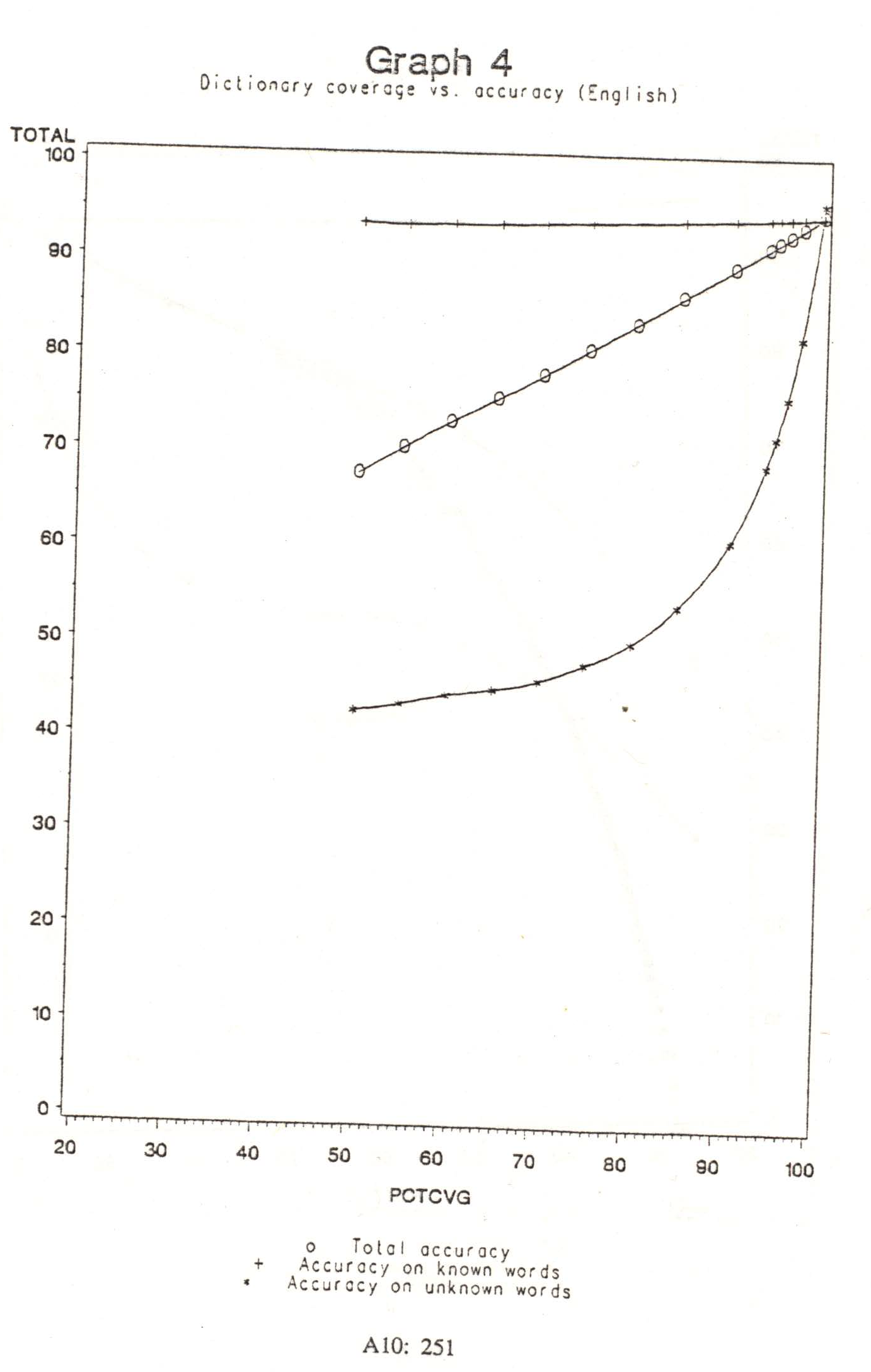
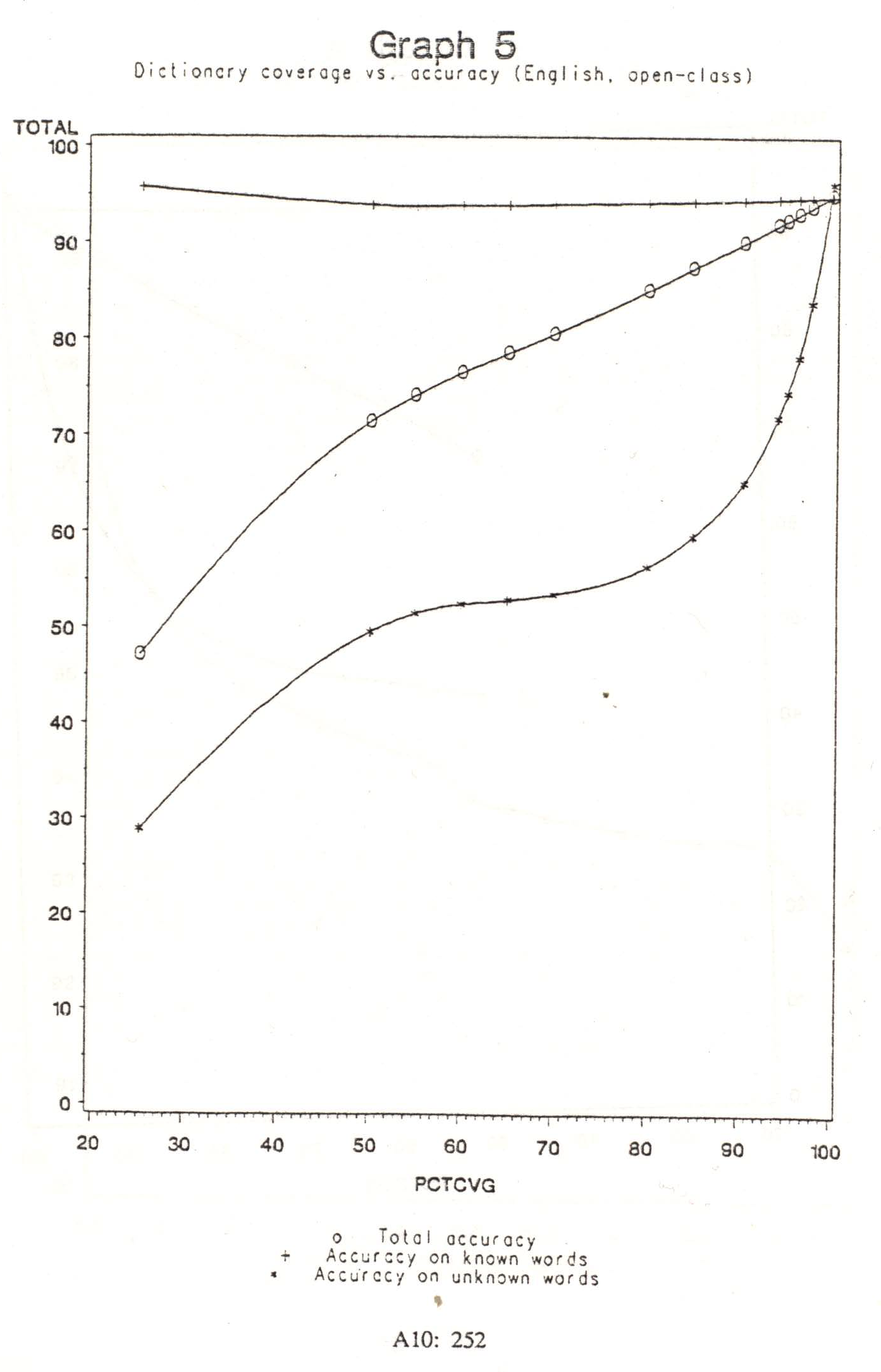
The first variation involved modifying the set of eligible tags. One possibility was to consider all tags. However, a substantial dictionary is likely to include virtually all words which are members of closed classes, and so unknown words are expected to be members of open classes. Thus a second possibility was to ignore closed class tags, treating them as entirely ineligible for assignment to words. Disregarding closed classes had a significant effect on accuracy, which effect increased as the dictionary‘s coverage of the target text decreased. This relationship is displayed in Graphs 4 and 5; the latter reflects considering only the open classes to be eligible for assignment to unknown words.
The second variation involved the maximum number of candidate tags assigned to an unknown word (prior to disambiguation), as opposed to the number of eligible tags overall. That is, the apparent degree of ambiguity of unknown words could be limited. Investigations with maxima of 8 and 16 showed no discernible effect on tagging accuracy.
The third variation involved the method of choosing candidate tags from among eligible tags. Consider the following example: a word which can be either NN (noun) or VB (verb), is followed by an unknown word.
One method was to check all eligible tags as successors to NN, and make the best (or potentially the best n) into candidates. The process was then repeated to make a candidate of that eligible tag which proved the best successor to VB. This provided each unknown word the same number of potential tags as the preceding word.
The second method was to pool all the probabilities of potential tag pairs (i.e., each tag of the preceding word, followed by each eligible tag). Then the n most probable candidates overall were chosen, rather than choosing separately for each possible predecessor tag. This method might choose only candidate tags which were highly probable successors to the same tag of the preceding word, in effect stranding the other tags of the preceding word. For example, this can be DT (determiner) or QL (qualifier); it could be that the top several possible collocations for an unknown word following this all have DT as their predecessor tag. In this case no tag candidate would be chosen which had a higher probability of following QL, and the the QL use of this would be more or less stranded.
The second method proved to have a slight advantage in terms of overall accuracy, about 0.15%. In these investigations I treated unknown words as having equal RTP values for all their candidate tags. Another possibility is to assign RTPs based upon the overall tag frequencies for known words. In that case, it would be best to consider only the tag frequencies for known but uncommon words, since the tag frequencies of common and uncommon words are unlikely to be the same. For example, particular proper nouns are in general quite rare, though as a class they are frequent.
These investigations of dictionary coverage do not exhaust the methods which could be used to increase accuracy on unknown words. An obvious example, suffix analysis, is a standard method for categorizing unknown word forms, and is often accurate. Particularly in the case of the text I checked manually, it seemed that even rudimentary suffix analysis would account for many cases. More or less complex collocational analyses could also be done for unknown words, seeking an optimal trade-off between expense and accuracy.
I investigated dictionary size by causing the word-look-up portion of the tagger to ignore any word forms listed in the dictionary as having a total frequency (in the Brown Corpus) less than some threshold value. Thus rare words were lost first, followed by successively more common words. In the extreme case, only the top 11 word types remained, accounting for 25% of all tokens.99.5
As a variation one could delete words from the dictionary on another ordering principle than frequency. Words could be lost at random, by grammatical category, or even partially lost, with particular forms being known only sometimes; such methods would relate more closely to studies of lesioning in models of natural language processing.99.6
Graph 4 shows the relationship between the total percentage of word tokens which the dictionary covers, and the resultant accuracy. Total accuracy and accuracy specific to known and unknown words, are all shown. Graph 5 shows the same information as Graph 4, but for the case where only open class tags were eligible. Because of the lack of numeric and similar types in the dictionary, the extreme right ends of these graphs represent approximately, not exactly, complete dictionary coverage.
Accuracy on known words was barely affected at all, showing less than a 2% decrease even at only 50% dictionary coverage. In fact, at 25% coverage the accuracy for the 11 word forms known was higher than that obtained with a full dictionary. This slight drop in the middle range occurred because errors in tagging an unknown word occasionally throw off the probabilities enough to affect tag assignment for neighboring known words.
Over a large range the effect on total accuracy was nearly linear. However, below 60% coverage (which represents 408 word forms), accuracy began to drop more rapidly. Presumably this is because function words, which supply a great deal of structural information, then began to be lost.
Over the linear portion of the graph, approximately every 2 tokens not covered amounted to a token tagged wrong. Thus, dictionary size was not found to be as crucial as might be thought; even having just the function words helped a great deal. Reasonable results can be obtained even with a small dictionary. Still, it is prudent to avoid the lower portions of this graph for use on unrestricted text. Fortunately even a tiny dictionary (by today‘s standards) of 3,000 word forms should cover about 80% of text, and not even 10,000 forms are required to cover over 90%. Because of Zipf‘s law, only high coverage will generally be of importance.
Accuracy in tagging unknown words dropped very rapidly as dictionary coverage decreased. With the full dictionary, the few words still missing (numbers, etc.) were actually tagged slightly more accurately than known words; this is consistent with the earlier finding that the baseline accuracy is high for those particular classes of unknown words. However, the accuracy for unknown words fell to 75% even with a 5% decrease in dictionary coverage. Fortunately the precipitous drop did not continue; this reflects that as the dictionary shrank, the algorithm approached a point at which it could exploit only the structural information provided by (generally high frequency) function words, and there is a certain accuracy, well above zero, which can be obtained based on that information alone. Also for this reason, the accuracy again began to drop more rapidly from 60% coverage downwards, as function words finally began to be lost.
Restricting unknown words to being assigned only open classes increased accuracy. At 50% dictionary coverage this step added about 4% to the total accuracy, and about 7% to the accuracy of tagging the unknown words themselves. It also provided a significant speed-up, since the task of choosing candidates takes time which can range as high as the number of eligible tags times the maximum number of candidates of the preceding word. This worst case occurs when adjacent words are unknown, since unknown words are given more candidate tags than the average known word has. Of course the worst case occurs more frequently as dictionary coverage decreases; at very low coverage the time difference can be significant.
The second control study split the Brown Corpus roughly in half, treating each half as an independent body of text. Separate dictionaries and collocational probability tables were built from each half, which thus reflected only the words and tag sequences evidenced in the individual halves. Each half was then used as the normalization basis for tagging both itself (the ipsilateral case, which is also isometric) and the other half (the contralateral case, which is not isometric). I divided the Corpus near the end of Genre G, with the first half
(581,293 tokens) ending up slightly larger than the second (555,559 tokens).
With 30% RTP weight, this investigation produced the results reported in Table 13. The # Tokens Unknown
column shows the number of unknown word tokens in the target text; note that this includes the punctuation and numeric tokens which are not included in the dictionaries. The % Tokens Unknown
column shows the corresponding percentage of unknown tokens. % Accuracy (Total)
is the overall accuracy; % Accuracy (Known)
is the accuracy specifically for known words, and % Accuracy (Unknown)
is the accuracy specifically for unknown words.
The unknown
words were of two types: first were numbers and other intentionally omitted types which have already been discussed. These were the only unknown words in the ipsilateral cases, and they were evidently very easy to tag. The second group included words which occur only in one of the corpus halves, and which therefore were unknown when the dictionary was built from the other half.
| Source | Target | # Tokens | % Tokens | % Accuracy | % Accuracy | % Accuracy |
| Half | Half | Unknown | Unknown | (Total) | (Known) | (Unknown) |
| 1st | 1st | 40,061 | 6.89 | 95.17 | 95.09 | 95.44 |
| 1st | 2nd | 64,079 | 11.53 | 91.03 | 93.80 | 69.79 |
| 2nd | 1st | 72,302 | 12.44 | 90.32 | 93.98 | 64.51 |
| 2nd | 2nd | 38,944 | 7.01 | 95.43 | 95.31 | 96.96 |
As with the disabled dictionary method, tagging errors were concentrated among the unknown words. Normalization appears to have been more adequate if based on the first half of the corpus than if based on the second. The latter basis discovered a smaller share of the needed words, had a lower overall tagging accuracy than the former, and had a 5% lower accuracy on unknown words. I attribute these differences mainly to the unusual vocabulary and syntax found in some genres of imaginative prose (found within the second half of the Corpus).
This control study could be varied by splitting the corpus in various ways to control for genre differences. One way would be to divide the corpus into even- and odd-numbered samples. The method I used, however, intentionally minimized the similarity of the halves. For example, all of the imaginative prose genres were kept in the same half. This minimized the possibility of discovering genre-specific knowledge from which more homogeneous normalizations might have benefited. Because of this choice, the performance obtained should be lower than it would be in the more homogeneous case, and more generalizable to unrestricted text.
The third control study consisted of tagging a 5,000 word sample of newspaper text which was available, and manually checking the tagging accuracy.103.7 As noted earlier, manual checking is notoriously prone to error, and I may not have precisely the same intuitions as those who participated in tagging and checking the Brown Corpus. Further, I would concur with Johansson when he points out that words often do not fit obviously into one category or another, that categories cannot always be sharply separated, and that tagging is an interpretation of the texts
(Johansson 1985, p. 216; see also Aarts and van den Heuvel 1982, p. 72). However, the results were generally encouraging.
I used the normal Brown Corpus tag set, and applied both collocational probabilities and RTPs, with RTPs weighted at 30%. Only open class tags were considered in cases where word forms were unknown to the dictionary. The most common error was missed proper nouns, since case distinctions were not present in the source text. Nearly all of these could be handled easily if case information is available, and so I have counted this class of error separately.103.8 Another notably frequent error was adjective vs. noun, which other writers have frequently suggested is difficult (e.g., Milne 1986, p. 4; Francis 1980, p. 204). The most frequent substantial error seemed to be noun vs. verb, in many forms (often solvable by suffix analysis). Cases of to + infinitive were sometimes taken to be preposition + noun, again not a surprise.
I found an 11% error rate, including the easily reparable cases, which is in keeping with the nonisometric results measured automatically for other texts (such as the halves of the Brown Corpus). Subtracting just the proper noun errors, the error rate dropped to 7%, which is not far from the accuracy found isometrically. Rudimentary suffix analysis would catch a significant percentage of the residual errors.
This test was quite small, but certainly indicates that the accuracy figures to be expected for unrestricted text are not vastly different from those found in the nonisometric and other control cases.
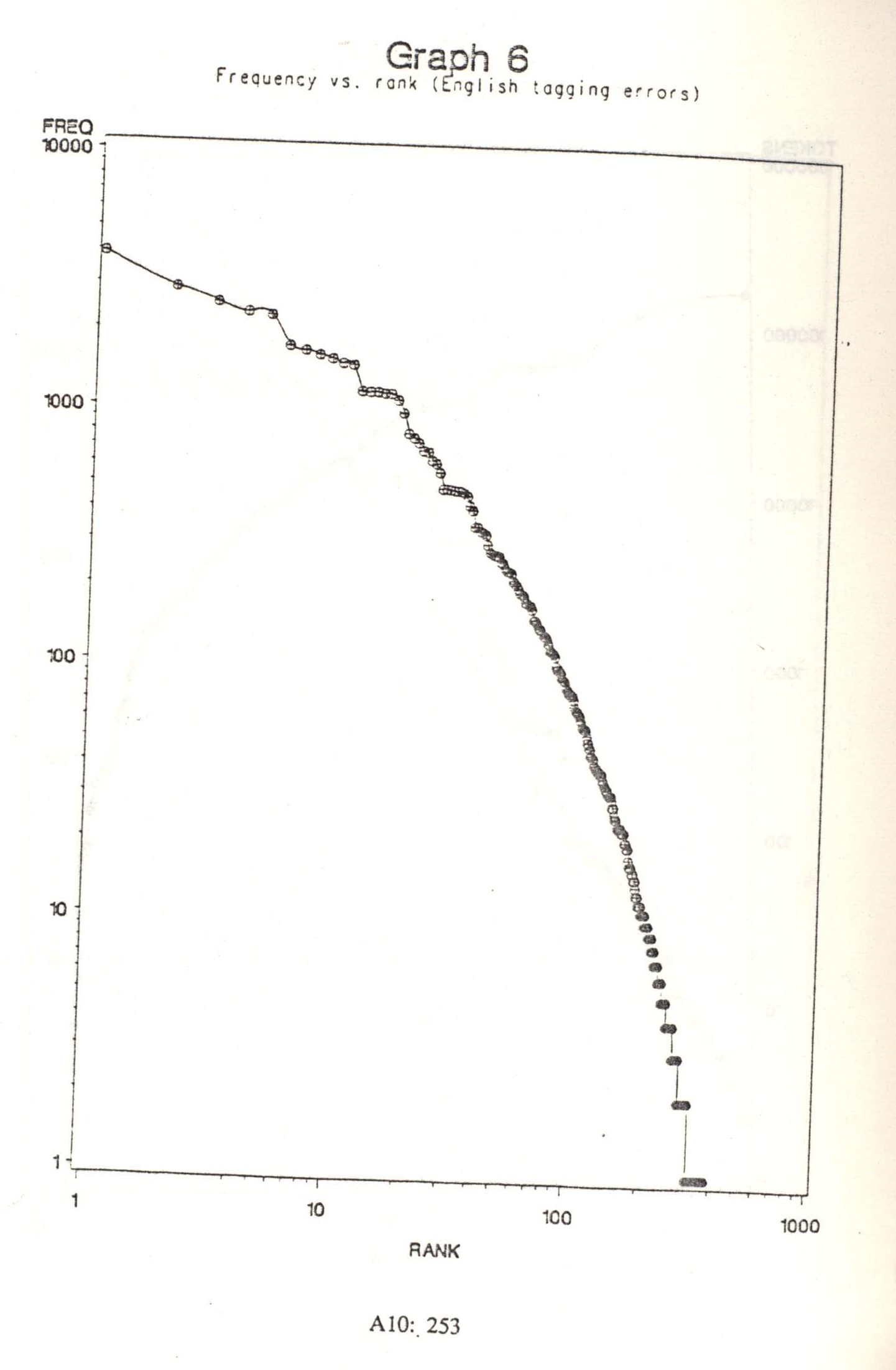
Appendix 6 shows the types of tagging errors which occurred, using 30% RTP weighting and no RASs for English.104.9 Study of the particular errors which occurred may suggest refinements to the stochastic disambiguation method. For example, extra analysis (stochastic or of another kind) could be devoted specifically to the most error-prone cases. I therefore have included three sub-lists of errors. First, there is a list showing the number of times each actual tag occurred in the Brown Corpus, but was not correctly assigned by Volsunga. Second, a list shows the number of times Volsunga assigned each tag erroneously. And third, a list shows the frequencies of all ordered pairs consisting of a correct tag and its assigned but erroneous tag. The lists are sorted in decreasing order of frequency, and by the tags involved. Marshall (1987) discusses the types of errors encountered when using the CLAWS disambiguator on the LOB corpus.
The range of accuracies with which specific actual tags were correctly matched by the tagger is great. Fortunately the number of tags with poor accuracy was very small, and those tags tend to be infrequent. The number of tags with a given specific accuracy increases with the accuracy, so that 10 tags had accuracies in the 90%-95% range and 44 (half the tag set) had accuracies over 95%, including 17 tags which were never missed. All tags with specific accuracies of under 60% are listed here in Table 14 (this information is extracted from the complete table in Appendix 6).
| Tag | Total Tokens | Pct. of Corpus | Total Errors | Pct. of AllErrors | Specific Accuracy |
| HVN | 237 | 0.02 | 236 | 0.41 | 0.42 |
| RBT | 101 | 0.01 | 97 | 0.17 | 3.96 |
| WQL | 181 | 0.02 | 157 | 0.28 | 13.26 |
| ABL | 357 | 0.03 | 304 | 0.53 | 14.85 |
| DTX | 104 | 0.01 | 82 | 0.14 | 21.15 |
| RN | 9 | 0.00 | 7 | 0.01 | 22.22 |
| JJS | 380 | 0.03 | 202 | 0.36 | 46.84 |
| WPO | 286 | 0.03 | 140 | 0.25 | 51.05 |
| WPS | 3982 | 0.35 | 1679 | 2.95 | 57.84 |
The worst case is a bit of a surprise: HVN, the tag which marks had
in its use as a past participle. This was doubtless a consequence of the RTP data swamping collocational information for this word form: there are 4,997 instances of had as HVD, the simple past tense form. RBT (superlative adverb) was also seldom correctly assigned, again probably because the available alternative JJT (morphologically superlative adjective) is so much more frequent overall.
One noteworthy feature of Table 14 is that even taken together, the tags shown account for only 5.10% of all tagging errors. If WPS (nominative wh- pronoun), which is both the most accurate of the group (at 57.84%) and the most frequent (over half the total errors, and over two thirds of the tokens accounted for by the group), then the remaining errors account for only 2.15% of all errors made in tagging the Brown Corpus.
A complete table of how often each tag was assigned when it should not have been, appears in Appendix 6, sorted by the number of such errors per tag. The most frequent misassignments are also shown here in Table 15.
| Tag Name | Times Assigned Erroneously |
| NN | 11451 |
| IN | 7321 |
| CS | 5910 |
| JJ | 4332 |
| VBN | 4072 |
| RB | 3577 |
| QL | 1898 |
Noun was, not surprisingly, the most frequent such error. This was due to it being a likely candidate in a wide range of collocational contexts, and being so relatively frequent for many word forms. Prepositions (IN) were frequently misassigned because of their wide variety of alternative uses. IN is a possible tag in over 40 distinct ambiguity sets, often alternating with adjective, noun, and adverb, but with many other categories as well.
Table 16, below, shows the several most frequent error pairs found when tagging the Brown Corpus. Graph 6 illustrates the rank-frequency relation for errors (as ordered pairs). Note that these data keep reverse errors distinct. For example, the error of tagging a conjunction as a preposition (one such ambiguous word is until
) is counted separately from the error of tagging a preposition as a conjunction.
| Rank | Actual Tag | Assigned Tag | Error Frequency |
| 1 | VBD | VBN | 3931 |
| 2 | VB | NN | 2913 |
| 3 | JJ | NN | 2562 |
| 4 | CS | IN | 2358 |
| 5 | VBG | NN | 2300 |
| 6 | DT | CS | 1752 |
| 7 | VBN | VBD | 1687 |
| 8 | WPS | CS | 1631 |
| 9 | TO | IN | 1571 |
| 10 | RP | IN | 1521 |
| 11 | PPO | PPS | 1496 |
| 12 | QL | RB | 1184 |
| 13 | NP | NN | 1180 |
| 14 | : | . | 1177 |
| 15 | RB | IN | 1163 |
| 16 | VBZ | NNS | 1160 |
| 17 | QL | CS | 1098 |
| 18 | RB | JJ | 981 |
| 19 | IN | RP | 817 |
| 20 | NN | JJ | 788 |
| 21 | AP | JJ | 752 |
| 22 | PPO | PP$ | 703 |
| 23 | IN | TO | 694 |
| 24 | RB | QL | 643 |
| 25 | IN | CS | 625 |
| 26 | PPO | PPSS | 575 |
Perhaps the most notable item in this table is the high frequency of CS (subordinating conjunction) vs. IN (preposition) errors. These errors were due mainly to temporal connectives such as before
, after
, and until
. A colon was also sometimes erroneously tagged as a sentence end; this is an actual ambiguity which the Brown Corpus distinguishes, and which is complex enough to be given special attention in manuals of style (e.g., University of Chicago Press 1982, pp. 148-150).
Although had had the worst specific accuracy, that appears to have posed the most complicated disambiguation problem, followed by to. That can function in a variety of ways, including (examples are from the Brown Corpus):
That was the only word form representing precisely that ambiguity set. To
was the only word form found to function as IN (preposition), NPS (plural noun), QL (qualifier), or TO (infinitive marker).108.10 Among the 17 error types that occurred over 1,000 times, consider the following cases (I also list the reverse errors here):
| Actual | Assigned | Occurrences | Words of that ambiguity Set |
| DT | CS | 1752 | that, thet109.11 |
| WPS | CS | 1631 | that |
| TO | IN | 1571 | to |
| QL | CS | 1098 | that, so |
| CS | QL | 343 | that, so |
| CS | DT | 115 | that, thet |
| CS | WPO | 20 | that |
| IN | TO | 694 | to |
| WPO | CS | 136 | that |
| 5095 | Total for that, thet, so | ||
| 2265 | Total for to |
The 7,360 errors accounted for by these few word forms, to which it is easy to relate particular lexical items, constitute nearly 13% of all errors. The 12,582 total occurrences which include that (10,595), thet (3), and so (1984) had a 40% error rate, indicating that this particular type of disambiguation was a major source of error. The 26,149 occurrences of to had an 8.6% error rate, also much higher than average.
These lexical items have also been shown to be difficult by other authors, notably Milne (1986), who devotes specific discussions to to, that, her, have, what, and which. Francis (1980) discusses a number of particularly difficult classes of words which were uncovered during verification of the Brown Corpus tags. Among them are words ending in -ing, which may be participles, adjectives, or nouns; prenominal modifiers; hyphenated or potentially hyphenated compounds; and others.
Information theory is the study of fundamental aspects of problems encountered in information generation, storage, and transmission
(Jelinek 1968, p. v). Jelinek (1968) and Smith (1973) provide background and historical information on this field; in this section I will be concerned primarily with rank-frequency relations and related properties of entropy (as defined earlier).
The relationship between the rank of a word form when all word forms are ordered by frequency (the is rank 1, of rank 2, etc.), and the frequency of the word at that rank, is the best known example of a Zipfian relationship. That is, the expected frequency of the nth-ranked word form is proportional to 1/n. However, it is not obvious whether the same relationship should be expected for the frequencies of more abstract elements such as grammatical categories per se, or collocations of categories. In this section I present the relationships found for these elements.
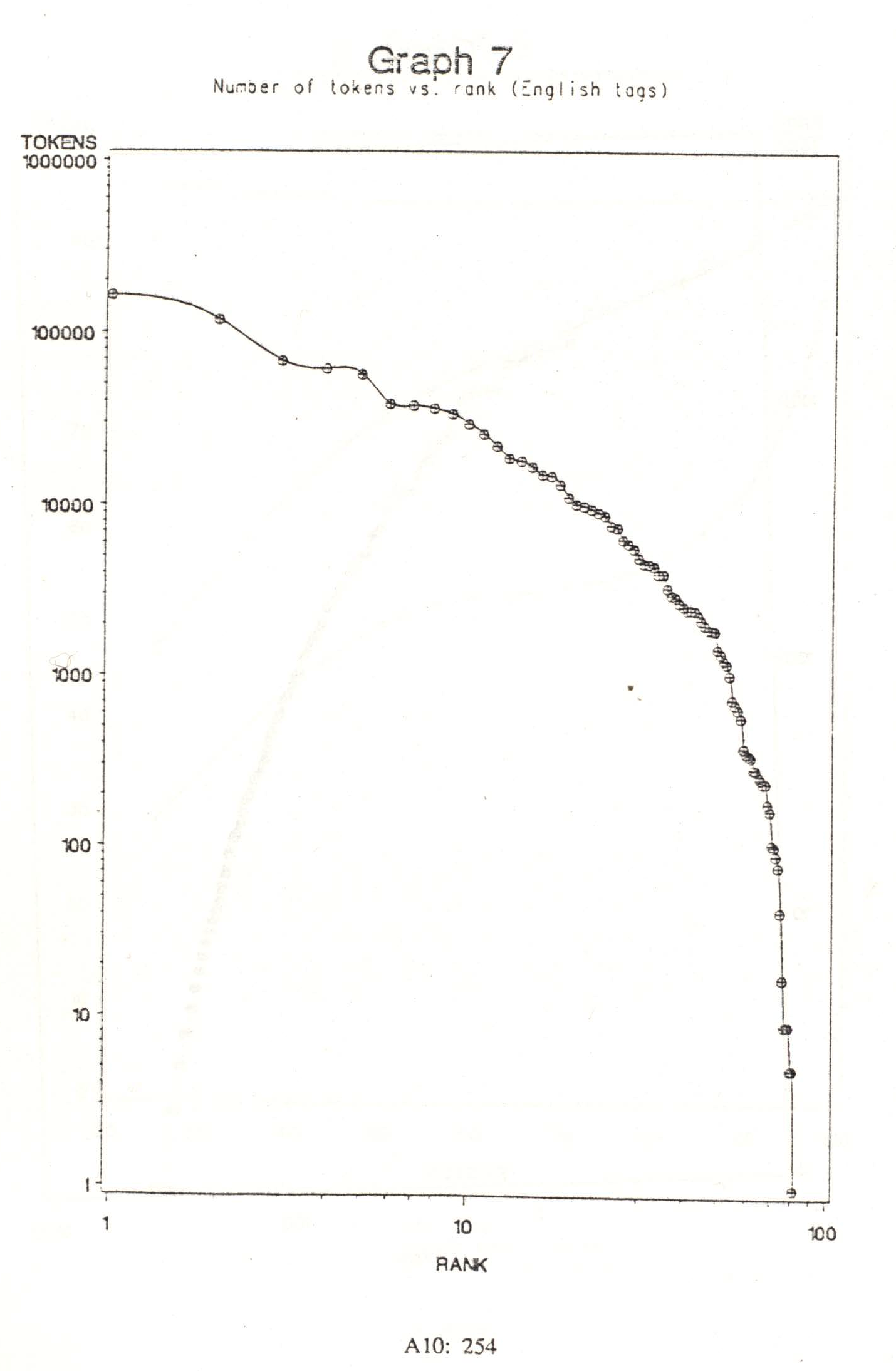
A tag‘s frequency may be counted in two ways: by the number of types which can represent it, or by the total number of tokens which it labels. Having generated a dictionary with tags and frequencies from the Corpus, I derived the table included in Appendix 3, which shows the total number of types and tokens for each distinct tag (not including punctuation tags).
Graph 7 shows that the rank-frequency relationship for the number of tokens per tag does not conform to Zipf‘s law. It drops off much too steeply, but more importantly it does not remain linear over a significant portion of its range.
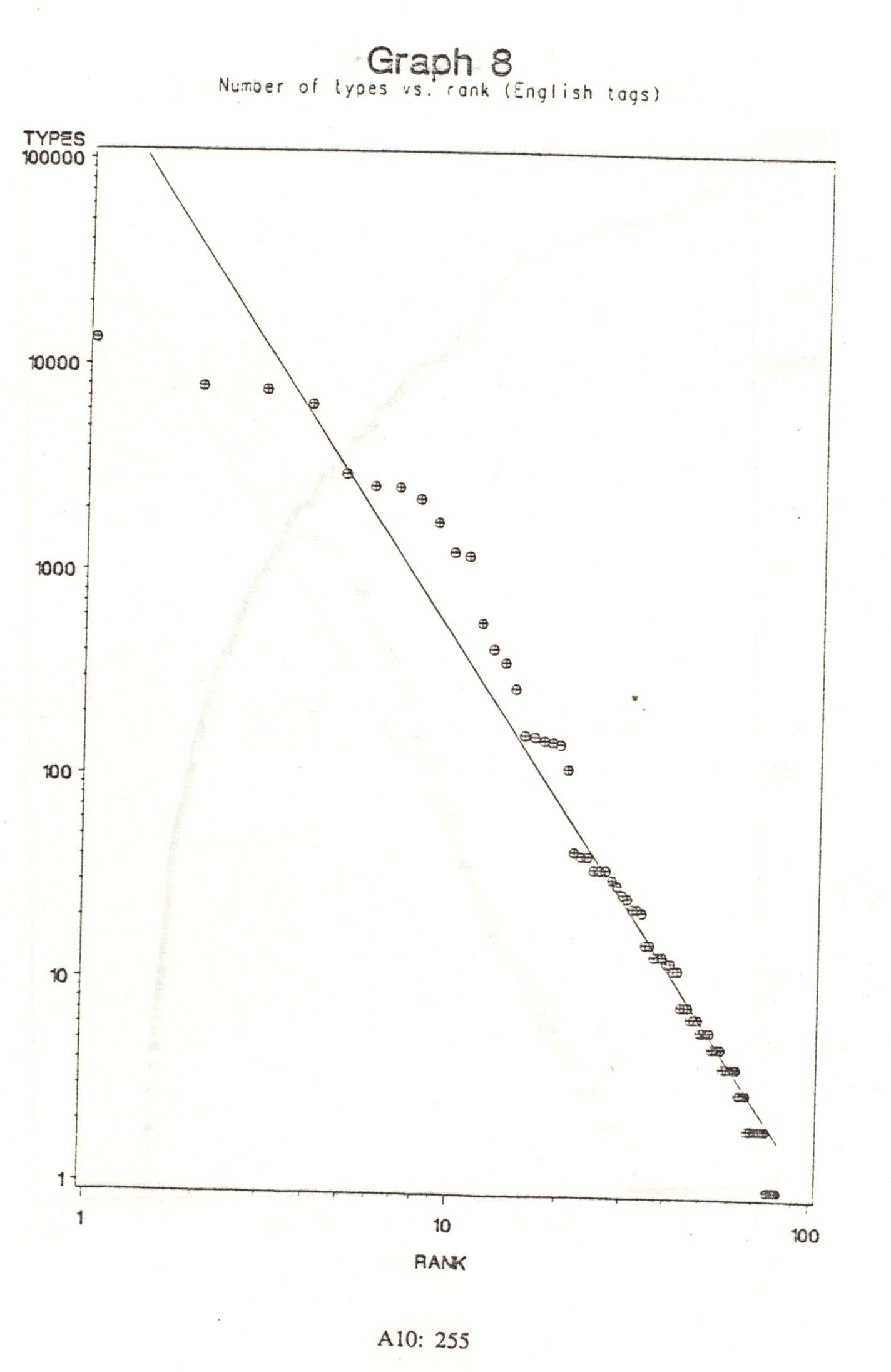
Graph 8 shows the relationship for the number of types (word forms) per tag. This graph does remain more or less linear over much of its course; only the most frequent few tags deviate greatly from the projected line, and Zipf‘s law frequently does not apply at the ends, i.e., at very high and very low ranks. However, the slope of the line is far steeper than -1, being approximately -3.5. This means that the frequency of the nth-ranked tag is proportional to 1/n3.5. In Zipf‘s terms, a steep slope would imply that the Force of Unification
greatly outweighs the Force of Diversification
(Zipf 1949, pp. 129-131). In more precise terms, it means that there are very few tags which are represented by many types; this is to be expected, because the number of open classes, which tend to be populous, is very small. This is also why better results were obtained in tagging unknown words when only open class tags were considered eligible to be assigned them.
I have done similar counts for ambiguity sets. Appendix 4 shows the numbers of types and tokens representing each ambiguity set. From these tables one can determine the number of ambiguous and unambiguous forms and tokens for any category, and the prevalence of any ambiguity set of interest. Perhaps not surprisingly, the most frequent ambiguity set in terms of total tokens is NN vs. VB, represented by 38,845 instances. However, there are more types representing VBD vs. VBN (1,483 as against 935).
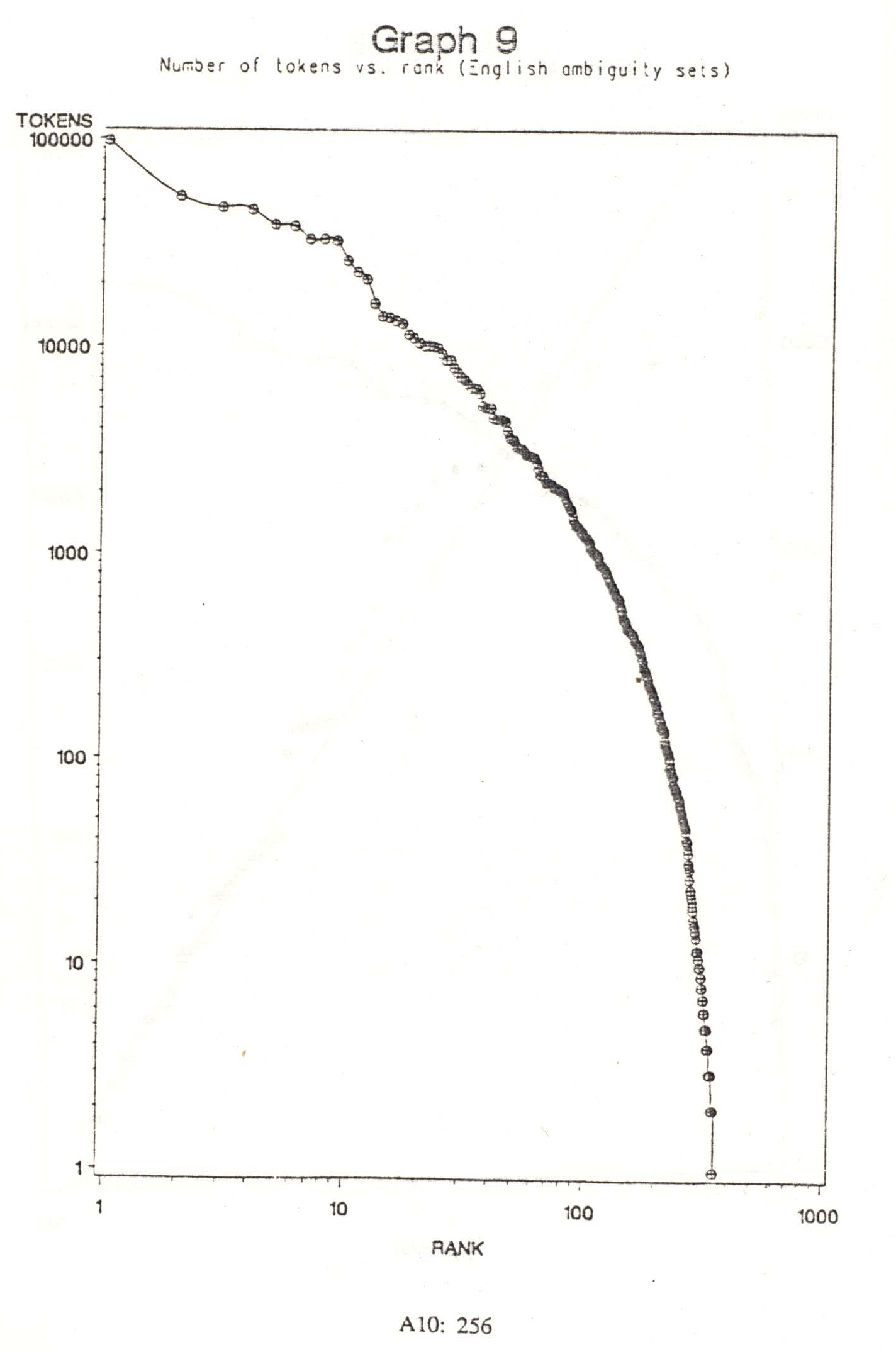
Graph 9 shows the rank-frequency relationship for the number of tokens per ambiguity set. As with Graph 7, the relationship is not linear, indicating that this relationship is not adequately modelled by Zipf‘s law.
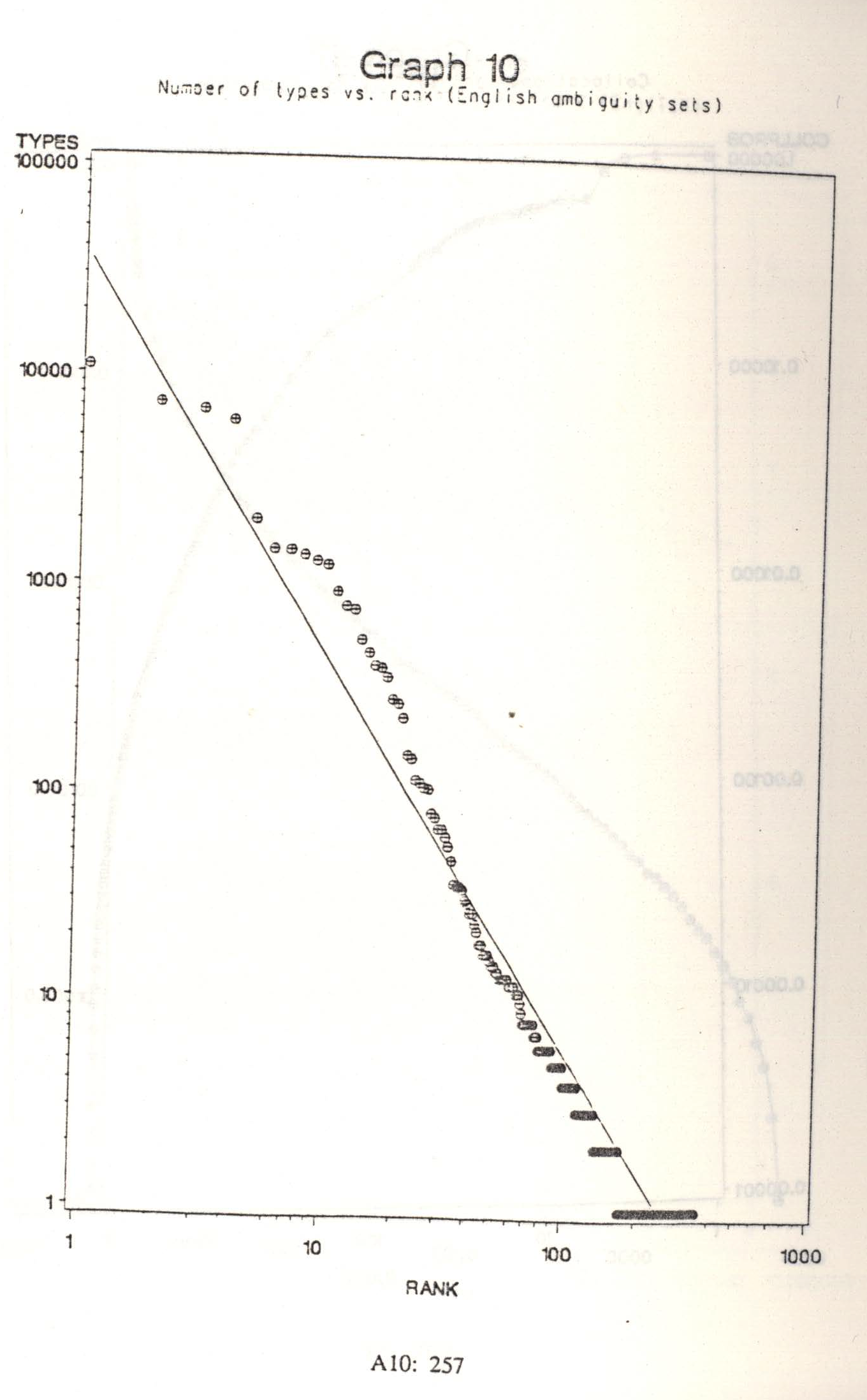
Graph 10 shows the relationship for the number of types (word forms) per ambiguity set. This relationship does remain approximately linear over a large range, with a slope only slightly less steep than Graph 8, at about -2.5.
As usual with lexical phenomena, in all these cases items occurring only rarely should be treated with caution. For example, the only type which has the ambiguity set including CC (co-ordinating conjunction) and VBD (past tense verb) is et.
111.12 The conjunctive use is probably due to embedded Latin phrases; the verbal use is apparently a dialect form of ate
(see Francis and Kučera 1982, p. 139). This particular ambiguity set clearly is accidental, and does not reflect a systematic derivational relationship between the categories involved. Half the ambiguity sets have only one type each, and deserve particular caution.
I conclude that grammatical categories did not show a Zipfian rank-frequency relation at all when measured in terms of the number of tokens to which they apply. The number of types per tag may be interpretable in Zipfian terms, but only with an exponent substantially greater than 1.
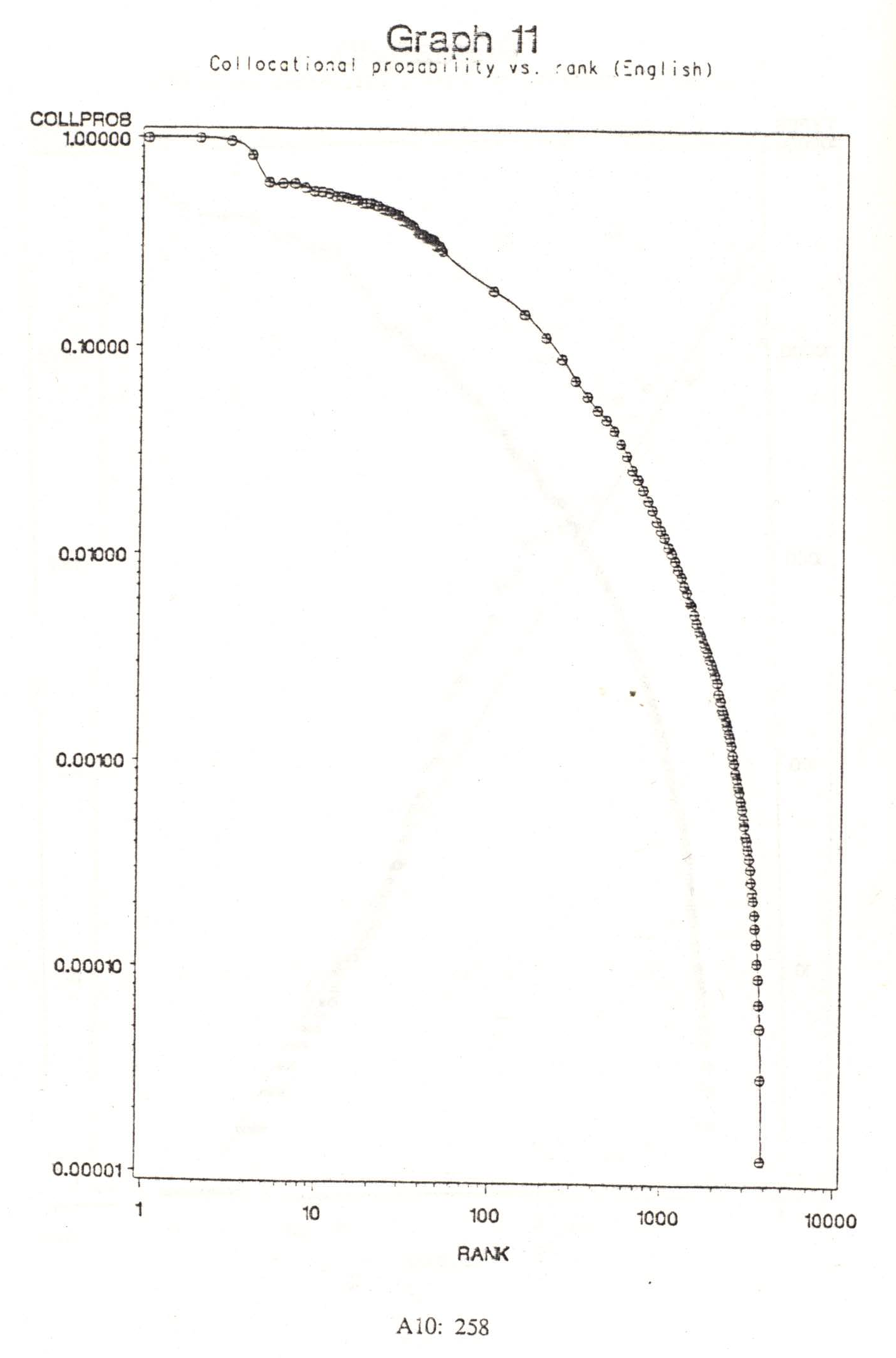
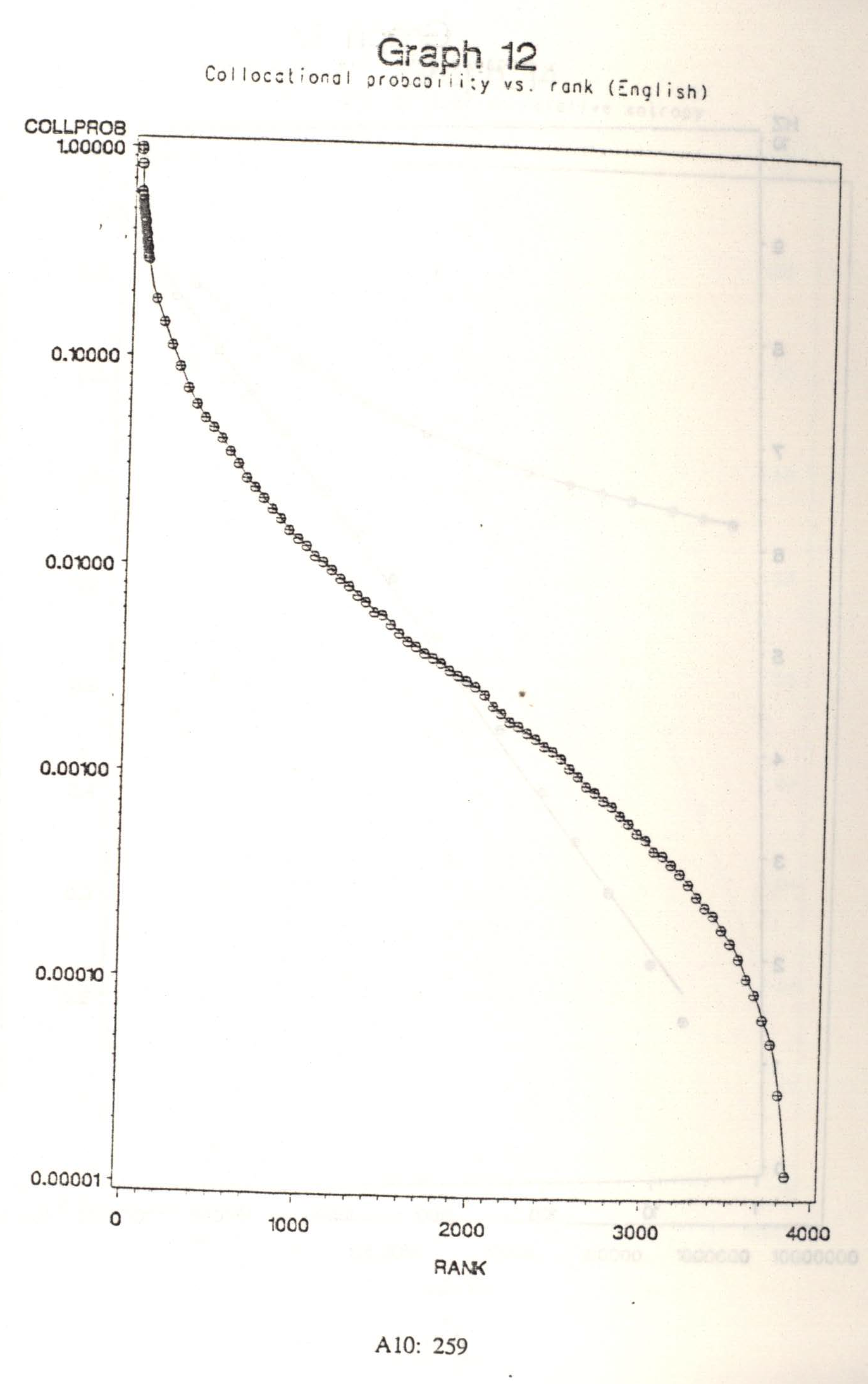
A table of collocational probabilities is provided in Appendix 5, from which graphs 11 and 12 have been derived. These graphs illustrate that the rank-frequency relation for collocational probabilities is more nearly negatively logarithmic than strictly Zipfian (allowing as usual for distortion at the ends). The first few hundred collocations, however, are substantially more probable than the curve would otherwise predict, indicating that they carry a minimal information load and thus contribute greatly to redundancy. These graphs should be interpreted in relation to the findings, discussed in the next section, that (a) the cumulative entropy does appear to reach a stable value once a sufficient amount of text is examined, and (b) the cumulative number of collocations found with increasing normalization corpus size does not appear to converge to any value less than the entire set of potential pairs.
Church (1988, p. 142) reports that a third order collocational probability table for English approximately
follows Zipf‘s law. I did not find the same to be true of second order collocational probabilities. Church‘s finding may differ from mine because there is actually a difference between the characteristics of second and third order relations, because there are idiosyncratic differences in the data used in each case, or because there are differences in the latitude we permit a function still said to approximately
follow Zipf‘s law.
In this section I derive the entropy of an ideal Zipfian source, and compare it to the actual entropy of the English and Greek corpora.
The importance of Zipfian distributions, particularly for words, suggests the question, What is the entropy of an ideal Zipfian source?
Zipf‘s law predicts the frequency of vocabulary items in a corpus of given vocabulary and length. First order entropy is defined solely in terms of the probabilities of vocabulary items, and the probabilities of those items can in turn be determined from their frequency in a corpus of given size. Therefore, one can directly obtain the first order entropy of an ideal Zipfian source of given vocabulary and length. In fact the corpus length is not needed; the expected entropy can be determined solely from the vocabulary size. I here derive the equation for the entropy of a Zipfian source, making use of the following symbols:
C — Size of corpus
V — Size of vocabulary
H — Entropy
Fi — Frequency of vocabulary item i
Pi — Probability of vocabulary item i
The equations in the following derivation may not all be correct MathML yet.
| Step | Proposition | Basis |
| 1. | Zipf‘s law | |
| 2. | Definition | |
| 3. | 1, 2 | |
| 4. | Factor out constant | |
| 6. | Divide by sum | |
| 7. | 1, 6 | |
| 8. | Arithmetic | |
| 9. | Definition | |
| 10. | 8, 9 | |
| 11. | Defn of Entropy | |
| 12. | 10, 11 | |
| 13. | Factor out sum | |
| The partial sum of 1/i cannot, to my knowledge, be reduced to a closed-form expression, and the series does not converge (although the corresponding series for 1/iB for all B>1 do converge). Knuth (1973, p. 74) offers the following approximation for the nth partial sum, with e, the maximum error of the approximation, such that 0 < e < 1/(256n6): | ||
| 14. | ||
| γ is Euler‘s constant (0.57721 56649...). For n in the thousands, as with corpus applications, the fractional corrections are negligibly small. Applying the consequent simpler approximation, 13 simplifies to: | ||
| 15. | ||
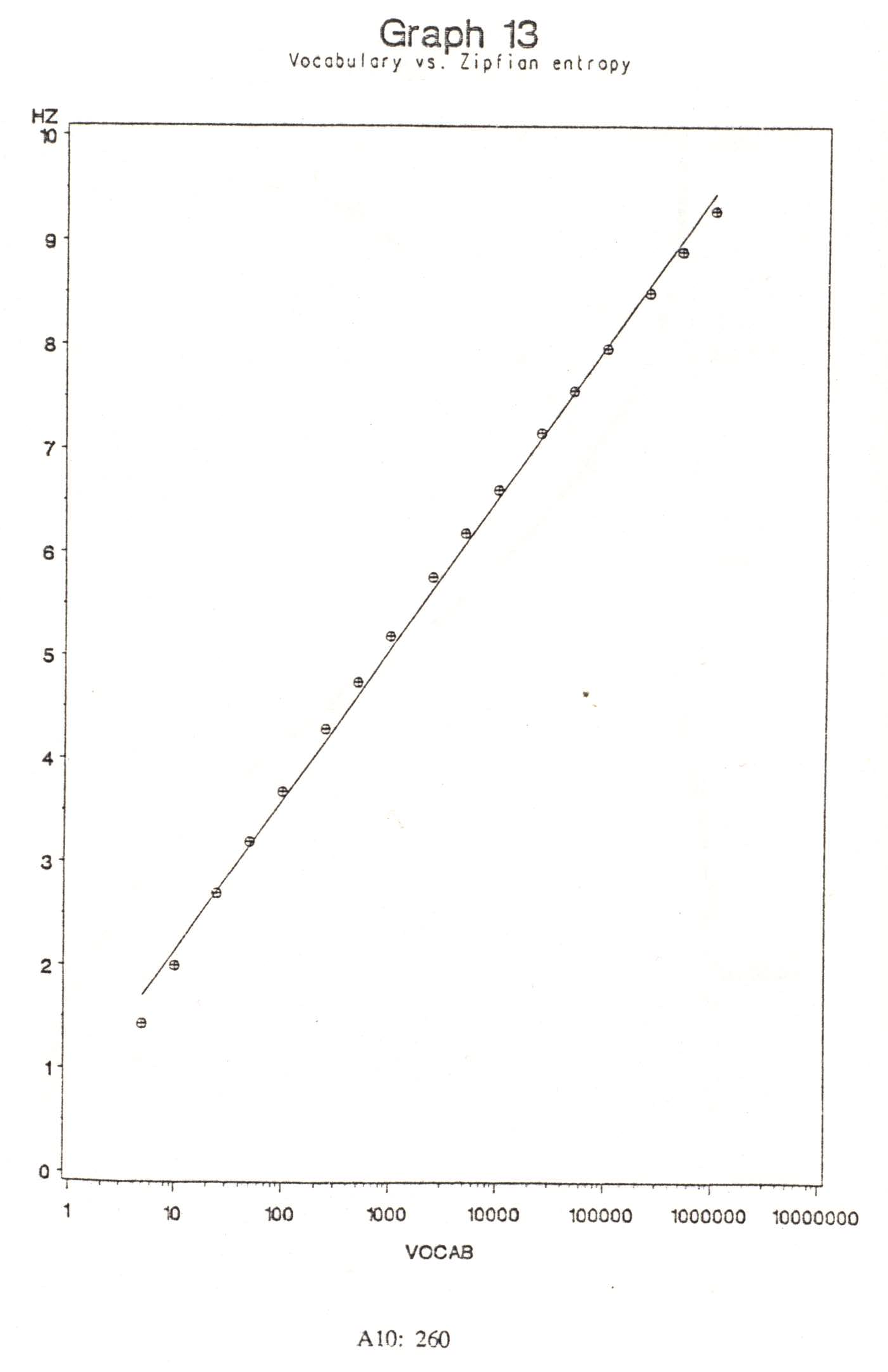
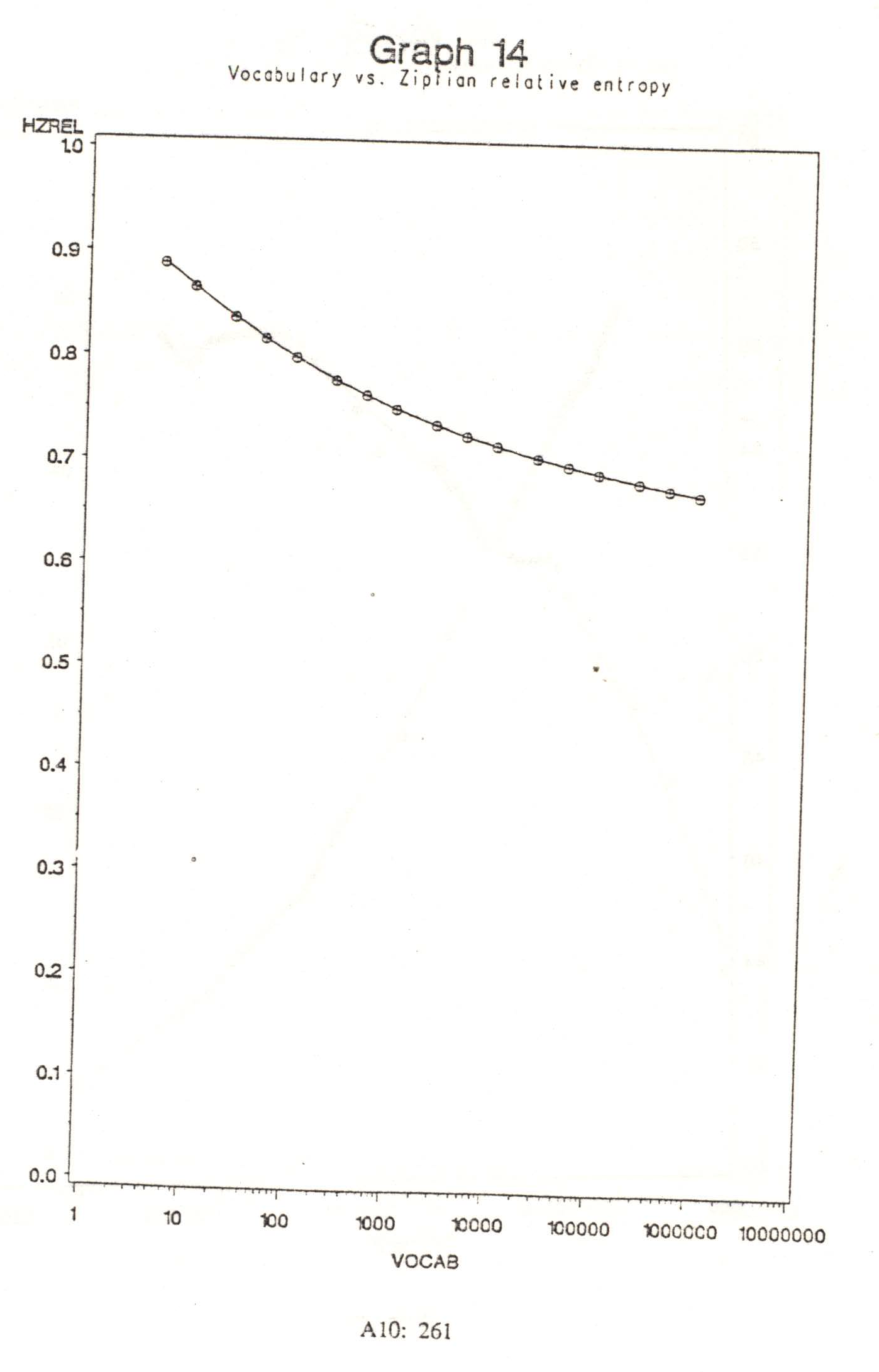
As expected the ideal Zipfian entropy (which I will denote Hz) depends only on the number of symbols in the vocabulary. Graph 13 plots Hz (calculated via the equation in step 13) against vocabulary size, for values from 10 to 1,000,000. Hz increases almost steadily as the vocabulary increases exponentially. Graph 14 plots the corresponding figures for relative entropy. HzRel in fact decreases with increasing vocabulary. The specific values for the symbol set sizes used in this research are shown in Table 18.
| Language | Symbols | Hz | HzMax | HzRel |
| English | 88 | 3.593 | 6.459 | 80.245% |
| English/RAS | 911 | 5.132 | 9.831 | 75.310% |
| Greek | 1155 | 5.282 | 10.1745 | 74.900% |
Table 19 shows the first and second order entropy for tags as derived from the tag frequencies and collocational probabilities generated from the English and Greek corpora. The same information is supplied for the English resolved ambiguity tag set.
Greek is generally considered to have quite free word order; thus it is surprising to find lower relative entropy figures for Greek tags than for the standard English tags. Lower entropy entails higher redundancy and should reflect higher predictability of successive categories. One factor which surely affects the apparent entropy is that freedom of word order is mainly present at a high level: major constituents are more easily shifted than are most individual words within a constituent.
The fact that English showed lower relative entropy with RASs than with atomic tags is not surprising. The larger set of categories encodes more structural information as evidenced by the higher tagging accuracy, and hence would be presumed to have higher redundancy.
| Language | Order | H | HMax | HRel | HRel/HzRel |
| English | First | 4.758 | 6.459 | 73.66% | 0.917 |
| Second | 3.642 | 6.459 | 56.39% | ||
| English/RAS | First | 6.299 | 9.832 | 64.06% | 0.851 |
| Second | 4.929 | 9.832 | 50.13% | ||
| Greek | First | 7.131 | 10.174 | 69.87% | 0.932 |
| Second | 5.030 | 10.174 | 49.29% |
Comparing the empirical and ideal figures shows that they agree within 10% except for the English RAS calculations; in all cases the empirically-determined entropy was smaller than the predicted Zipfian entropy, indicating that at least in terms of tag frequencies, natural language as represented by these corpora is slightly more redundant than a source with a pure Zipfian distribution. This is particularly true for the RAS data. The figures (again, especially the RAS data) could also reflect the fact that entropy increases with sample size, and that HzRel reflects a sample of infinite size; in that case we need merely assume that the corpora used did not quite reach their languages‘ limiting values for entropy.
The seemingly counter-intuitive entropy figures led me to seek other factors which might affect entropy. One evident possibility is that some valid collocations were not attested; this was certainly the case for the Greek corpus.
The relative entropy will be lowered if some theoretically possible symbols (whether words, tag, collocations, or other symbols) do not occur. This is because (for a given sample) the calculated entropy (H) remains the same, while the divisor used to convert to relative entropy (HMax) increases with increasing symbol vocabulary. For example, one could re-calculate the second order entropy shown above for the Brown Corpus, but assume that there are actually 100 tags, 12 of which simply do not occur in the Brown Corpus. HRel then would be only 3.642 / 6.643 or 54.8%, a reduction of 1.59%. If the corpus used to measure entropy is too small, some low-frequency collocations will not be attested; in the extreme case even some individual tags will be unattested, as is the case for the Greek New Testament (see below). Even in the Brown Corpus, 6 tags occur fewer than 10 times each, and could easily be missed in a smaller sample.117.13 Therefore I investigated the relationship of corpus size to entropy.
Jelinek (1968, p. 71) points out that entropy is zero if and only if one output is certain and all others impossible.
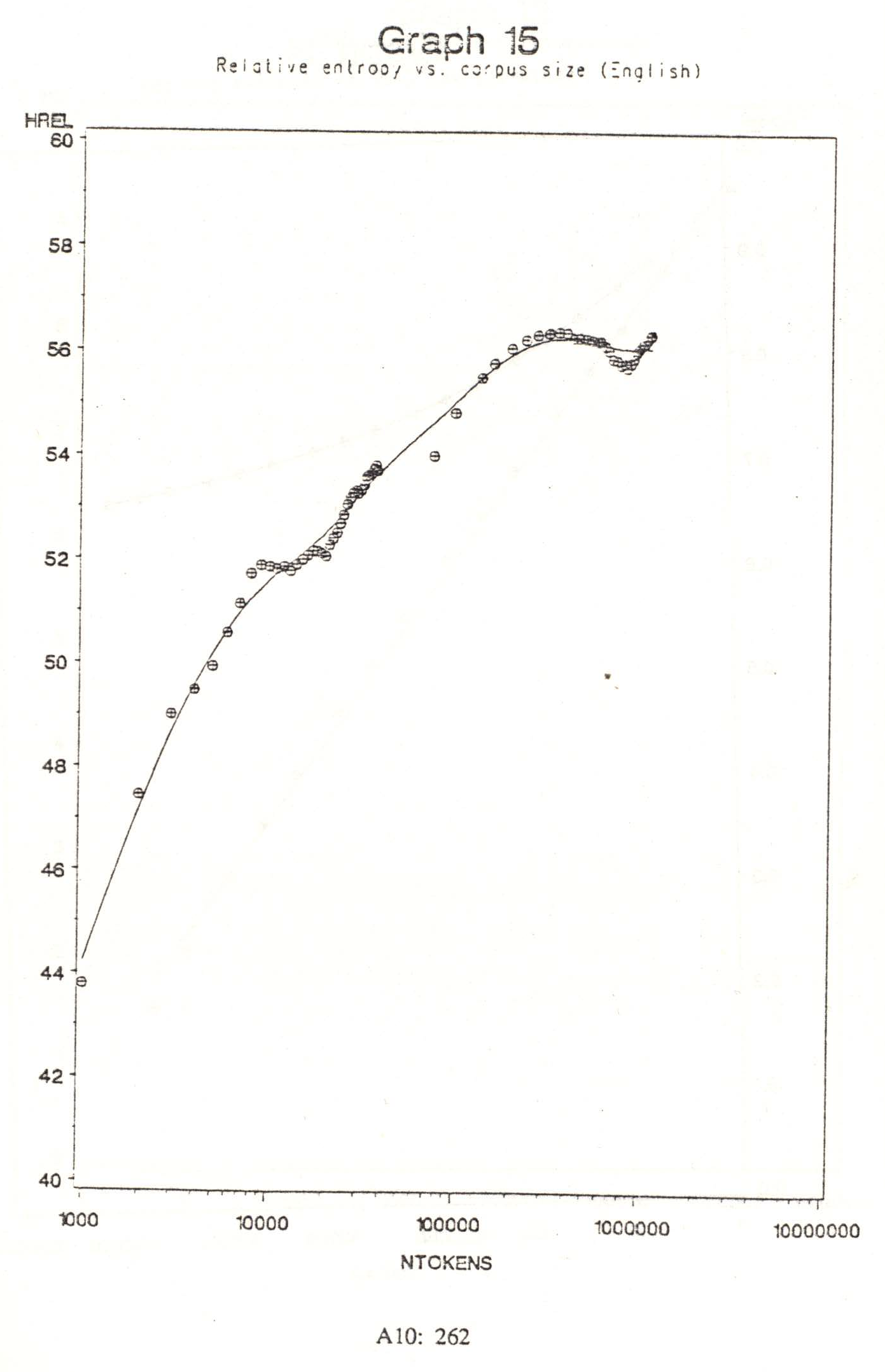
Thus the apparent entropy of a one-word sample is zero. Given a specific vocabulary, increasing amounts of text will reveal ever more uncertainty as rare but possible collocations gradually appear. The critical question then is how much text is enough? How much does it take to get to relatively stable entropy? Graph 15 shows the relationship of the second order entropy of English tags to the size of the text used to measure it: entropy rose somewhat less than logarithmically, to become fairly stable for the Brown Corpus after about 300,000 words.
Graph 15 does, however, show that the entropy declined slightly (and temporarily) after about 600,000 words. This is about where genre J (Learned prose) begins. Like the immediately following imaginative genres, it may be expected to contain significantly different syntactic structures from previous text. By the end of the Corpus, entropy regained its previous level, but the effect of a significant change of genre is clear; it is possible that the value would not remain stable beyond the 1 million words. Nevertheless, the effect of a significant change of genre is evidently not drastic (having led to a variation of less than 1 percentage point), and for a set of 88 tags 300,000 words seem to suffice.
The first order entropy for English tags reached a fairly stable value almost immediately. After only 300 tag occurrences had been counted, entropy reached nearly 68%; by 2,000 words it reached 70%. After that there was a very gradual climb to an ending value of just over 73%. I discuss the corresponding behavior of entropy for the Greek New Testament below.
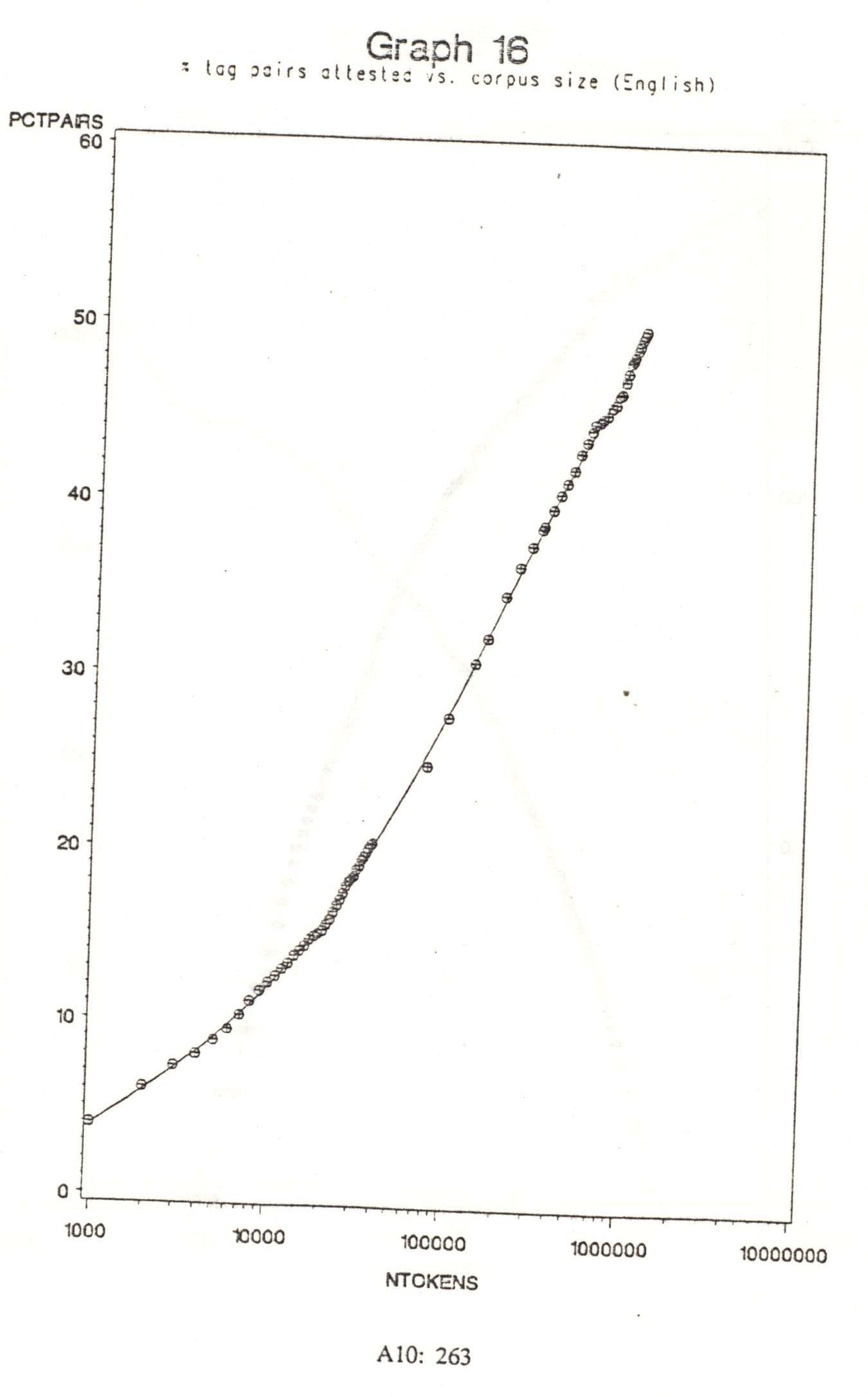
Graph 16 shows the percentage of the theoretically possible tag collocations attested in successively longer portions of the Corpus. By the end of the Corpus about half of all collocations were attested. The progression does not indicate that a limit was reached. On log-normal paper the increase is roughly linear, from 28% non-zero collocations with 100,000 words of normalization text, to 49% at 1 million. Extrapolation suggests that a corpus of 10 million words might reveal 70% of all theoretically possible tag pairs, and by 30 million words all might have been attested. Lackowski (1963) discusses several reasons why all collocations might occur; among them are metalinguistic and metaphorical uses of words. Nevertheless, since we have seen that entropy was fairly stable even after only 300,000 words, we may safely assume that the remaining collocations are of low enough probability so as not to materially influence entropy; thus they should not greatly affect tagging accuracy.
Analysis of the disambiguation algorithm‘s accuracy for the Greek New Testament was carried out in the same general manner as for the Brown Corpus, but in less detail. The uncommonly large set of 1155 tags raised certain difficulties. First, it was not practicable to analyze tagging accuracy using (the still larger set of ) RASs for Greek. Second, discoveries about entropy suggested that corpus size is a dominant factor in the results obtained for Greek. Given such a small tagged corpus, only isometric tagging was investigated. The Greek tag set is described in Appendix 7; Greek tag frequencies in the New Testament are listed in Appendix 8; a table of Greek contractions is in Appendix 9. It is worth noting that there are many expected tags, especially for verbs, which do not occur even once. For example, A--AFYP, and VIPE--XS, and many more.
Graphs 17 and 18 show the rank-frequency relation for Greek tags. The curve is substantially smoother than found for English, due perhaps in part to the larger tag set; but as with English the progression is not purely harmonic as one might predict based on Zipf‘s law.
The baseline accuracy for Greek, calculated by the dictionary method described above, was just under 90%. If all ambiguous words were to be tagged incorrectly, the accuracy would be about 58%. These figures are quite close to those found for English, indicating that however much the categorial ambiguity in Greek differs in kind from that of English (i.e., being mainly differences in minor category assignment such as gender), the total degree of ambiguity is much the same.
Collocational probabilities used alone gave an accuracy of 93.6%. Thus Owen‘s suggestion that the probabilistic approach to tagging will work best of all with languages whose linear order is relatively fixed
seems not to be supported (Owen 1987, p. 25), particularly since the total percentage of ambiguous forms is comparable for the Greek and English corpora which I am using.
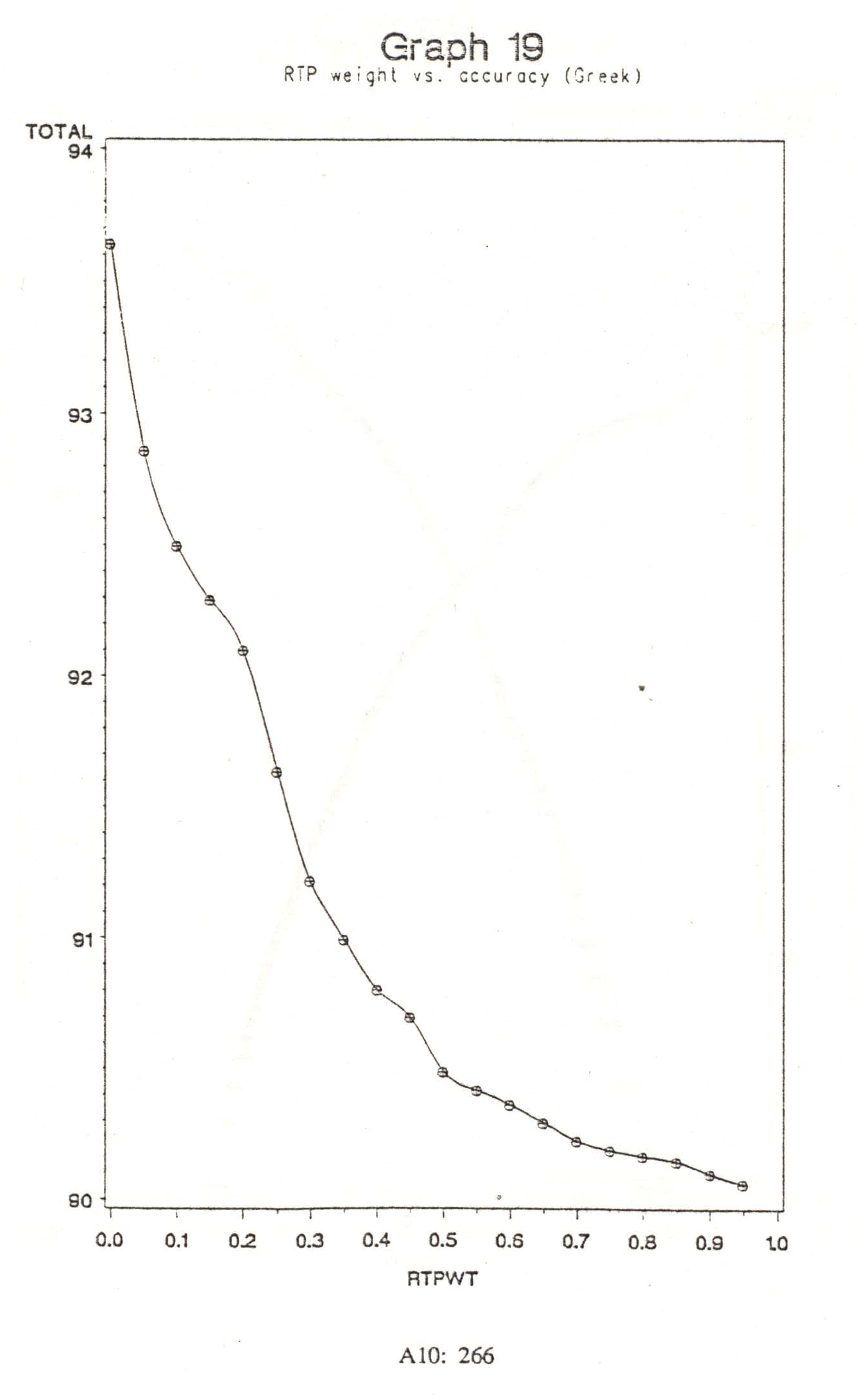
In Greek I found a phenomenon similar to that found with RASs in English: RTPs were of no use. Graph 19 shows that accuracy decreased monotonically with increasing RTP weight; the best accuracy was obtained with no RTPs as all. This may be due to the small corpus size in relation to the number of word forms: the mean frequency of a word form in the Greek NT is 142,648 / 18,613 or 7.6, whereas in the Brown Corpus it is 1,014,232 / 50,406 or 20.1 (based on Kučera and Francis 1967, p. 307). There may simply not be enough instances of ambiguous words in Greek to reveal their patterns. It is also important to notice that as with English RASs, the collocational probability table size is so high in relation to the corpus size that statistically reliable estimates of probabilities have not been reached. It may also be that minor-category ambiguities in Greek simply do not follow RTP patterns. The distribution of minor categories such as number and gender is governed by syntactic and semantic context, not primarily by individual lexical items, and so RTPs should not matter for Greek.
The cumulative second order entropy for Greek tags continued to rise rapidly over the entire length of the Greek New Testament. Unlike with the Brown Corpus, the entropy in Greek did not show a hint of approaching stability. This is entirely plausible, for on the reasonable supposition that stability arises when the significantly non-rare collocations have been attested, the required corpus size should be generally related to the collocational probability table size. The Greek table is nearly 175 times larger than the English table, and so would be expected to require a much larger normalization text before reaching stability.
The cumulative first order entropy for Greek tags rose steadily until it quite suddenly stabilized after about 50,000-60,000 words. For second order entropy in Greek, the normalization corpus would presumably have to be many times larger. If the operative criterion is the number of potential cells, then the required text length is proportional to the square of the tag set size, and something over 50 million words of text would be required. If one instead assumed (much less plausibly, in my opinion) that second order stability requires a directly proportional increase in corpus size over that required for first order stability, then using the factor found for English a mere 50,000 * (300,000/2,000) or 7,500,000 words would be required.
Regardless of how the required corpus size may in fact be related to tag set size, the Greek New Testament (at 142,648 tokens, only a tiny percentage of any likely projected need) remains much too small to provide adequate normalization. It is also likely that the second order entropy calculated for the Greek New Testament is well below the figure to be expected if a more adequately sized corpus were available. Furthermore, as mentioned already, there are many tags which are known to be valid for Greek words, but which are not attested in the New Testament; these would increase the table size even further, and also, presumably, the size of corpus required.
Another indication that normalization has not reached stability is that the collocational probability matrix for Greek is less than 2% non-zero, as opposed to about 50% for the English matrix. Further, if potential categories (which theory indicates are valid but which are not attested in the Greek New Testament) were considered, then HMax would rise, and so HRel would drop. Yet one might have expected a greater percentage of collocations to be allowed in Greek, in accordance with its reputed free word order — this freedom, however, is mainly at the phrasal rather than the lexical level.
I also note that the first order entropy for Greek is much closer to the corresponding quantity for English than is the second order entropy. This is to be expected because (a) first order entropy does not reflect restrictions of category order, but only of category frequency; and (b) the Greek New Testament appears to be an adequate sample on which to base the calculation of first order entropy.
50 million words, a reasonable normalization corpus size for Greek, is nearly the projected size of the Thesaurus Linguae Graecae (TLG), a collection of all extant Greek literature from Homer... through A.D. 600 — almost 3,000 authors.
(Hughes 1987, p. 578). The TLG has not been grammatically tagged. Van der Steen (1982, p. 56) mentions a Luik Corpus
of tagged and lemmatized Greek texts, but gives no reference or other information; such a corpus is very unlikely to be large enough to help. Thus it seems unlikely that a tagged normalization corpus adequate for estimating second order entropy for Greek will become available in the near future. Even if it does, there will be little ancient Greek text left to which the results may be applied.
Certainly the greatest caution is justified in interpreting entropy figures from so small a Greek corpus. For the future, there are several ways in which one might investigate the relationship of tag set size and the size of normalization corpus required to achieve stability:
First, one could conduct tests on immense tagged corpora in multiple languages; this is not yet practical, though more corpora are becoming available, and it may be possible to test the hypothesis on languages with a moderate range of tag set sizes.
Second, one could create another version of the Greek New Testament, in which tags are grouped into a much smaller set of equivalence classes, and see how measures such as entropy and accuracy are affected by varying the (more nearly adequate) normalization corpus size. For example, subtle distinctions such as middle versus passive deponent forms could be deleted, participles with imperative sense
might be combined with participle or imperative, etc.
Third, it may prove possible to derive a theoretical prediction based on Zipfian or other theoretical distributions of tags and co-occurrences. For example, one can make the assumption of independence, that the probabilities of tag pairs are distributed as they would be if the text were generated by only a first order Markov model. The probabilities of specific tag pairs are then easily calculated, but the relationship of rank and probability is not so easily derived; indeed this approach turns out to be much less mathematically tractable than it may at first appear. Mandelbrot (1961) discusses some related analyses, as do Efron and Thisted (1976), Thisted and Efron (1987), and Hubert and Labbe (1988).
Next: Conclusions{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}